Redundant Array of Independent Disks (RAID) | Set 2
Last Updated :
03 Dec, 2019
Redundant Array of Independent Disks (RAID) is a set of several physical disk drives that Operating System see as a single logical unit. It played a significant role in narrowing the gap between increasingly fast processors and slow disk drives.
The basic principle behind RAID is that several smaller-capacity disk drives are better in performance than some large-capacity disk drives because through distributing the data among several smaller disks, the system can access data from them faster, resulting in improved I/O performance and improved data recovery in case of disk failure.
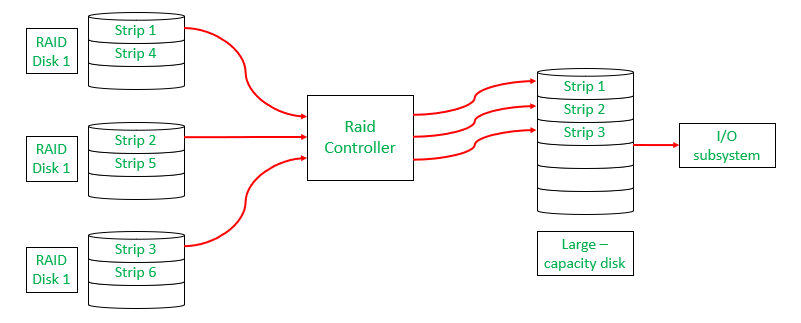
A typical disk array configuration consists of small disk drives connected to a controller housing the software and coordinating the transfer of data in the disks to a large capacity disk connected to I/O subsystem.
Note that this whole configuration is viewed as a single large-capacity disk by the OS.
- Data is divided into segments called strips, which are distributed across the disks in the array.
- A set of consecutive strips across the disks is called a stripe.
- The whole process is called striping.
Besides introducing the concept of redundancy which helps in data recovery due to hardware failure, it also increases the cost of the hardware.
The whole system of RAID is divided in seven levels from level 0 to level 6. Here, the level does not indicate hierarchy, but indicate different types of configurations and error correction capabilities.
Level 0 :
RAID level 0 is the only level that cannot recover from hardware failure, as it doesn’t provide error correction or redundancy. Therefore, it can’t be called the true form of RAID. However, it sure offers the same significant benefits as others – to the OS this group of devices appears to be a single logical unit.
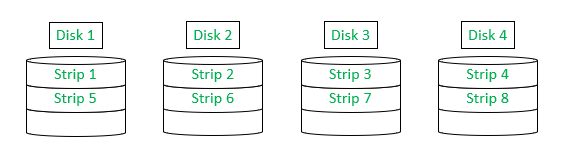
As illustrated above, when the OS issues a command, that can be transferred in parallel to the strips, improving performance greatly.
Level 1 :
RAID level 1 not only uses the process of striping, but also uses mirrored configuration by providing redundancy, i.e., it creates a duplicate set of all the data in a mirrored array of disks, which as a backup in case of hardware failure. If one drive fails, data can be retrieved immediately from the mirrored array of disks. With this, it becomes a reliable system.
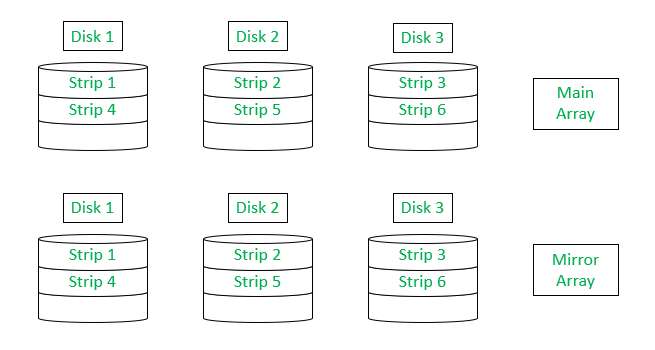
As illustrated above data has been copied in yet another array of disk as a backup.
- The disadvantage includes the writing of the data twice, once in main disks, and then in backup disks. However, process time can be saved by doing the copying the data in parallel to the main writing of the data.
- Another disadvantage is that it requires double amount of space, and so is expensive. But, the advantage of having a backup and no worry for data loss nullifies this disadvantage.
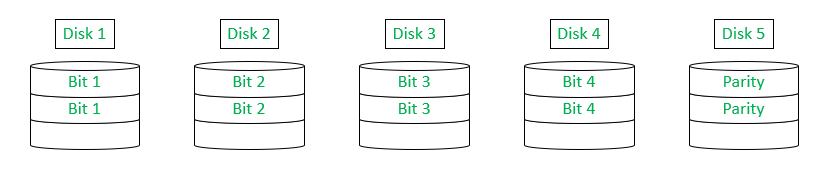
Level 2 :
RAID level 2 makes the use of very small strips (often of the size of 1 byte) and a hamming code to provide redundancy (for the task of error detection, correction, etc.).
Hamming Code : It is an algorithm used for error detection and correction when the data is being transferred. It adds extra, redundant bits to the data. It is able to correct single-bit errors and correct double-bit errors.

This configuration has a disadvantage that it is an expensive and a complex configuration to implement because of the number of additional arrays, which depend on the size of strips, and also all the drives must be highly synchronized.
The advantage includes that if a drive should malfunction, then only one disk would be affected and the data could be quickly recovered.
Level 3 :
RAID level 3 is a configuration that only needs one disk for redundancy. Only one parity bit is computed for each strip and is stored in designated redundant disk.
If a drive malfunctions, the RAID controller considers all the bits coming from that disk to be 0 and notes the location of that malfunctioning disk. So, if the data being read has a parity error, then the controller knows that the bit should be 1 and corrects it.
If data is being written to the array that has a malfunctioning device, then the controller keeps the parity consistent so as to regenerate data when the array is replaced. The system returns to normal when the failed disk is replaced and it’s contents are regenerated on the new disk(or array).
Level 4 :
RAID level 4 uses the same concept used in level 0 & level 1, but also computes a parity for each strip and stores this parity in the corresponding strip of the parity disk.
The advantage of this configuration is that if a disk fails, the data can be still recovered from the parity disk.
Parity is computed every time a write command is executed. But, when the data is to be rewritten inside the disks, the RAID controller must be able to update the data and parity disks. So, the parity disks need to be accessed whenever a write or rewrite operations are to be executed. This creates a situation known as the bottleneck which is the main disadvantage of this configuration.

Level 5 :
RAID level 5 is a modification level 4. In level 4, only one disk is designated for parity storing parities. But in level 5, it distributes the parity disks across the disks in the array.

The advantage of this configuration is that it avoids the condition of bottleneck which was created in level 4.
The disadvantage of this configuration is that during regeneration of data when a disk fails is complicated.
Level 6 :
RAID level 6 provides an extra degree of error detection and correction. It requires 2 different parity calculations.
One calculation is the same as the one used level 4 and 5, other calculation is an independent data-check algorithm. Both the parities are stored on separate disks across the array, which corresponds to the data strips in the array.
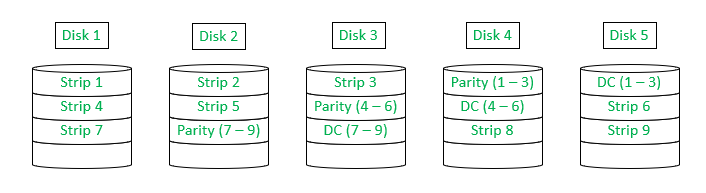
The advantage of this configuration is that if even 2 disks fails or malfunction, then also the data can be recovered.
The disadvantage of this configuration includes:
- The redundancy increases the time required to write the data because now the data is to be also written on the second parity disk.
- In this configuration another disk is designated as the parity disk, which decreases the number of data disks in the array.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...