r-Nearest neighbors
Last Updated :
16 Jun, 2022
r-Nearest neighbors are a modified version of the k-nearest neighbors. The issue with k-nearest neighbors is the choice of k. With a smaller k, the classifier would be more sensitive to outliers. If the value of k is large, then the classifier would be including many points from other classes. It is from this logic that we get the r near neighbors algorithm.
Intuition:
Consider the following data, as the training set.
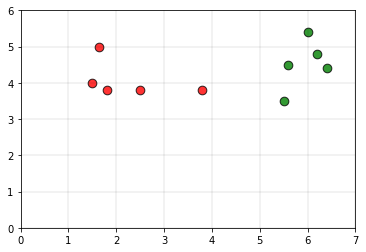
The green color points belong to class 0 and the red color points belong to class 1. Consider the white point P as the query point whose
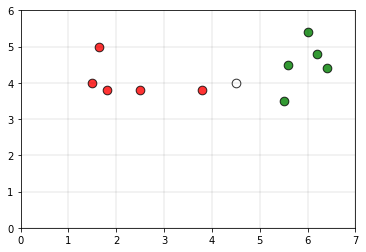
If we take the radius of the circle as 2.2 units and if a circle is drawn using the point P as the center of the circle, the plot would be as follows
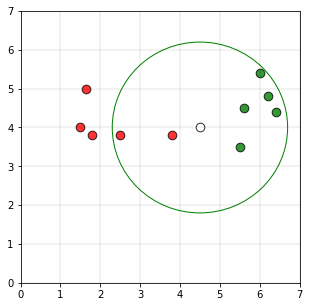
As the number of points in the circle belonging to class 1 (5 points) is greater than the number of points belonging to class 0 (2 points)
Algorithm:
Step 1: Given the point P, determine the sub-set of data that lies in the ball of radius r centered at P,
Br (P) = { Xi ∊ X | dist( P, Xi ) ≤ r }
Step 2: If Br (P) is empty, then output the majority class of the entire data set.
Step 3: If Br (P) is not empty, output the majority class of the data points in it.
Implementation of the r radius neighbors algorithm is as follows::
C++
#include <bits/stdc++.h>
using namespace std;
struct Point
{
int val;
double x, y;
};
int rNN(Point arr[], int n, float r, Point p)
{
int freq1 = 0;
int freq2 = 0;
for (int i = 0; i < n; i++)
{
if ((sqrt((arr[i].x - p.x) * (arr[i].x - p.x) +
(arr[i].y - p.y) * (arr[i].y - p.y))) <= r)
{
if (arr[i].val == 0)
freq1++;
else if (arr[i].val == 1)
freq2++;
}
}
return (freq1 > freq2 ? 0 : 1);
}
int main()
{
int n = 10;
Point arr[n];
arr[0].x = 1.5;
arr[0].y = 4;
arr[0].val = 0;
arr[1].x = 1.8;
arr[1].y = 3.8;
arr[1].val = 0;
arr[2].x = 1.65;
arr[2].y = 5;
arr[2].val = 0;
arr[3].x = 2.5;
arr[3].y = 3.8;
arr[3].val = 0;
arr[4].x = 3.8;
arr[4].y = 3.8;
arr[4].val = 0;
arr[5].x = 5.5;
arr[5].y = 3.5;
arr[5].val = 1;
arr[6].x = 5.6;
arr[6].y = 4.5;
arr[6].val = 1;
arr[7].x = 6;
arr[7].y = 5.4;
arr[7].val = 1;
arr[8].x = 6.2;
arr[8].y = 4.8;
arr[8].val = 1;
arr[9].x = 6.4;
arr[9].y = 4.4;
arr[9].val = 1;
Point p;
p.x = 4.5;
p.y = 4;
float r = 2.2;
printf("The value classified to query point"
" is: %d.\n", rNN(arr, n, r, p));
return 0;
}
|
Python3
import math
def rNN(points, p, r = 2.2):
freq1 = 0
freq2 = 0
for group in points:
for feature in points[group]:
if math.sqrt((feature[0]-p[0])**2 +
(feature[1]-p[1])**2) <= r:
if group == 0:
freq1 += 1
elif group == 1:
freq2 += 1
return 0 if freq1>freq2 else 1
def main():
points = {0:[(1.5, 4), (1.8, 3.8), (1.65, 5), (2.5, 3.8), (3.8, 3.8)],
1:[(5.5, 3.5), (5.6, 4.5), (6, 5.4), (6.2, 4.8), (6.4, 4.4)]}
p = (4.5, 4)
r = 2.2
print("The value classified to query point is: {}".format(
rNN(points, p, r)))
if __name__ == '__main__':
main()
|
Output:
The value classified to query point is: 1.
Other techniques like kd-tree and locality-sensitive hashing can be used to reduce the time complexity of finding the neighbors.
Applications: This algorithm can be used to identify outliers. If a pattern does not have any similarity with the patterns within the radius chosen, it can be identified as an outlier.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...