Queries to find total number of duplicate character in range L to R in the string S
Last Updated :
27 Mar, 2023
Given a string S of size N consisting of lower case alphabets and an integer Q which represents the number of queries for S. Our task is to print the number of duplicate characters in the substring L to R for all the queries Q.
Note: 1 ?N ? 106 and 1 ? Q? 106
Examples:
Input :
S = “geeksforgeeks”, Q = 2
L = 1 R = 5
L = 4 R = 8
Output :
1
0
Explanation:
For the first query ‘e’ is the only duplicate character in S from range 1 to 5.
For the second query there is no duplicate character in S.
Input :
S = “Geekyy”, Q = 1
L = 1 R = 6
Output :
2
Explanation:
For the first query ‘e’ and ‘y’ are duplicate characters in S from range 1 to 6.
Naive Approach:
The naive approach would be to maintain a frequency array of size 26, to store the count of each character. For each query, given a range [L, R] we will traverse substring S[L] to S[R] and keep counting the occurrence of each character. Now, if the frequency of any character is greater than 1 then we would add 1 to answer.
Efficient Approach:
To solve the above problem in an efficient way we will store the position of each character as it appears in the string in a dynamic array. For each given query we will iterate over all the 26 lower case alphabets. If the current letter is in the substring S[L: R] then the next element of the first element which is greater than or equal L to in the corresponding vector should exist and be less than or equal to R.
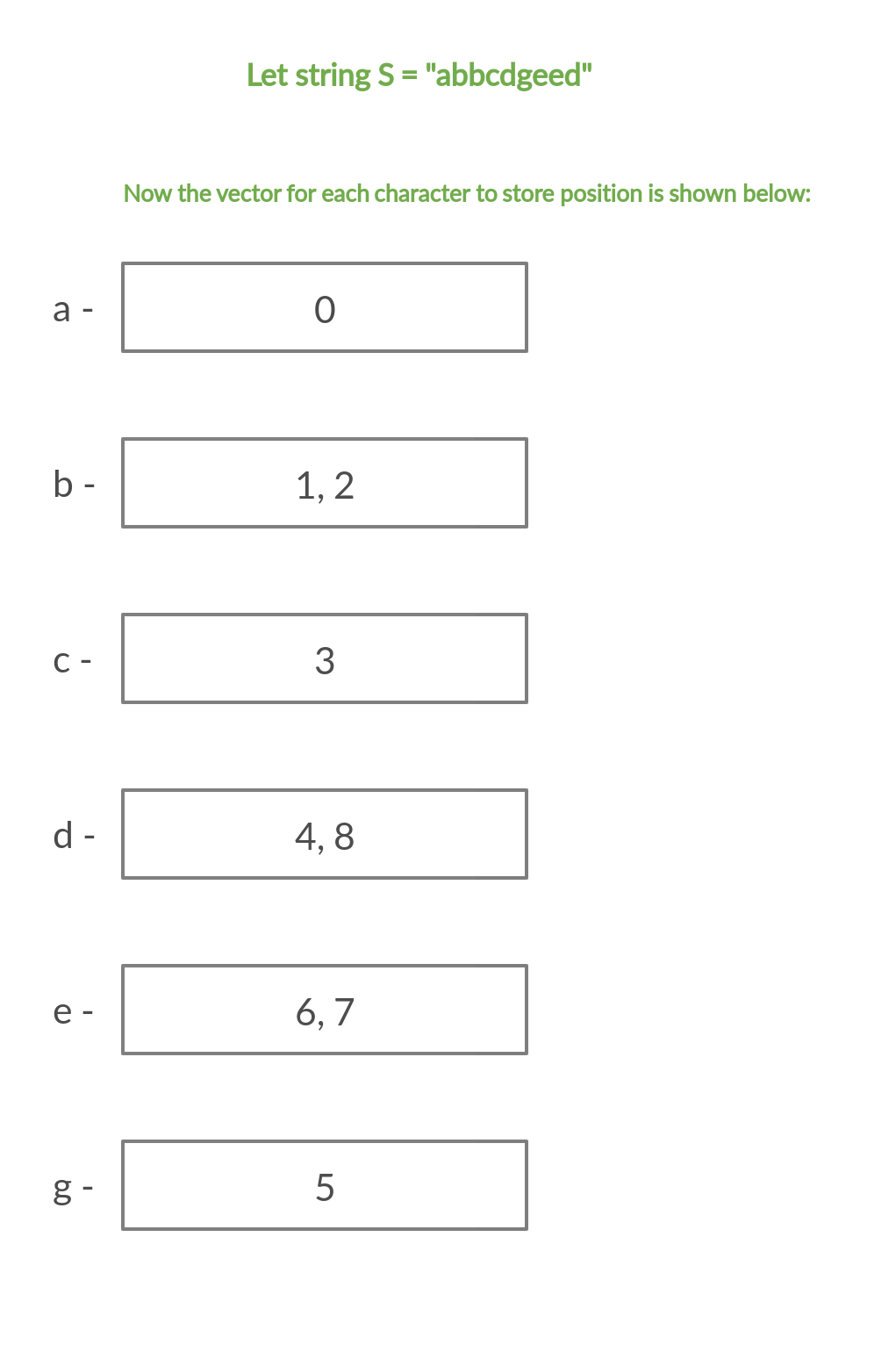
Diagram below shows how we store characters in the dynamic array:
Below is the implementation of the above approach:
CPP
#include <bits/stdc++.h>
using namespace std;
vector<vector<int> > v(26);
void calculate(string s)
{
for (int i = 0; i < s.size(); i++) {
v[s[i] - 'a'].push_back(i);
}
}
void query(int L, int R)
{
int duplicates = 0;
for (int i = 0; i < 26; i++) {
auto first = lower_bound(v[i].begin(),
v[i].end(), L - 1);
if (first != v[i].end() && *first < R) {
first++;
if (first != v[i].end() && *first < R)
duplicates++;
}
}
cout << duplicates << endl;
}
int main()
{
string s = "geeksforgeeks";
int Q = 2;
int l1 = 1, r1 = 5;
int l2 = 4, r2 = 8;
calculate(s);
query(l1, r1);
query(l2, r2);
return 0;
}
|
Python3
import bisect
v = [[] for _ in range(26)]
def calculate(s: str) -> None:
for i in range(len(s)):
v[ord(s[i]) - ord('a')].append(i)
def query(L: int, R: int) -> None:
duplicates = 0
for i in range(26):
first = bisect.bisect_left(v[i], L - 1)
if (first < len(v[i]) and v[i][first] < R):
first += 1
if (first < len(v[i]) and v[i][first] < R):
duplicates += 1
print(duplicates)
if __name__ == "__main__":
s = "geeksforgeeks"
Q = 2
l1 = 1
r1 = 5
l2 = 4
r2 = 8
calculate(s)
query(l1, r1)
query(l2, r2)
|
Java
import java.util.ArrayList;
import java.util.List;
public class DuplicateCharacter {
static List<List<Integer> > v = new ArrayList<>();
static void calculate(String s)
{
for (int i = 0; i < 26; i++) {
v.add(new ArrayList<>());
}
for (int i = 0; i < s.length(); i++) {
v.get(s.charAt(i) - 'a').add(i);
}
}
static void query(int L, int R)
{
int duplicates = 0;
for (int i = 0; i < 26; i++) {
int j = 0;
while (j < v.get(i).size()
&& v.get(i).get(j) < L) {
j++;
}
if (j < v.get(i).size()
&& v.get(i).get(j) < R) {
j++;
if (j < v.get(i).size()
&& v.get(i).get(j) < R) {
duplicates++;
}
}
}
System.out.println(duplicates);
}
public static void main(String[] args)
{
String s = "geeksforgeeks";
int Q = 2;
int l1 = 1, r1 = 5;
int l2 = 4, r2 = 8;
calculate(s);
query(l1, r1);
query(l2, r2);
}
}
|
Javascript
function bisect_left(arr, x) {
let lo = 0, hi = arr.length;
while (lo < hi) {
let mid = Math.floor((lo + hi) / 2);
if (arr[mid] < x) {
lo = mid + 1;
} else {
hi = mid;
}
}
return lo;
}
let v = [...Array(26)].map(() => []);
function calculate(s) {
for (let i = 0; i < s.length; i++) {
v[s.charCodeAt(i) - 'a'.charCodeAt(0)].push(i);
}
}
function query(L, R) {
let duplicates = 0;
for (let i = 0; i < 26; i++) {
let first = bisect_left(v[i], L - 1);
if (first < v[i].length && v[i][first] < R) {
first += 1;
if (first < v[i].length && v[i][first] < R) {
duplicates += 1;
}
}
}
console.log(duplicates);
}
let s = "geeksforgeeks";
let Q = 2;
let l1 = 1;
let r1 = 5;
let l2 = 4;
let r2 = 8;
calculate(s);
query(l1, r1);
query(l2, r2);
|
C#
using System;
using System.Collections.Generic;
public class DuplicateCharacter
{
static List<List<int>> v = new List<List<int>>();
static void calculate(string s)
{
for (int i = 0; i < 26; i++)
{
v.Add(new List<int>());
}
for (int i = 0; i < s.Length; i++)
{
v[s[i] - 'a'].Add(i);
}
}
static void query(int L, int R)
{
int duplicates = 0;
for (int i = 0; i < 26; i++)
{
int j = 0;
while (j < v[i].Count && v[i][j] < L)
{
j++;
}
if (j < v[i].Count && v[i][j] < R)
{
j++;
if (j < v[i].Count && v[i][j] < R)
{
duplicates++;
}
}
}
Console.WriteLine(duplicates);
}
public static void Main(string[] args)
{
string s = "geeksforgeeks";
int Q = 2;
int l1 = 1, r1 = 5;
int l2 = 4, r2 = 8;
calculate(s);
query(l1, r1);
query(l2, r2);
}
}
|
Time Complexity: O( Q * 26 * log N)
Auxiliary Space: O(N)
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...