Python program to Recursively scrape all the URLs of the website
Last Updated :
26 Mar, 2020
In this tutorial we will see how to we can recursively scrape all the URLs from the website
Recursion in computer science is a method of solving a problem where the solution depends on solutions to smaller instances of the same problem. Such problems can generally be solved by iteration, but this needs to identify and index the smaller instances at programming time.
Note: For more information, refer to Recursion
Modules required and Installation
Code :
from bs4 import BeautifulSoup
import requests
urls=[]
def scrape(site):
r = requests.get(site)
s = BeautifulSoup(r.text,"html.parser")
for i in s.find_all("a"):
href = i.attrs['href']
if href.startswith("/"):
site = site+href
if site not in urls:
urls.append(site)
print(site)
scrape(site)
if __name__ =="__main__":
scrape(site)
|
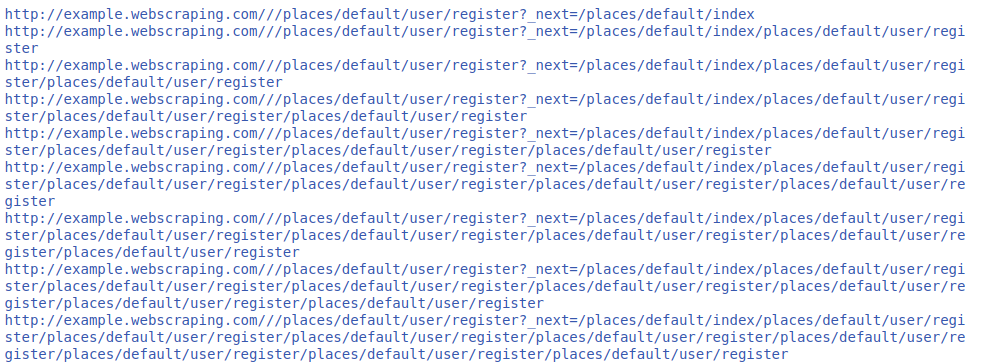
Output :
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...