Python | Positional Index
Last Updated :
13 Sep, 2021
This article talks about building an inverted index for an information retrieval (IR) system. However, in a real-life IR system, we not only encounter single-word queries (such as “dog”, “computer”, or “alex”) but also phrasal queries (such as “winter is coming”, “new york”, or “where is kevin”). To handle such queries, using an inverted index is not sufficient.
To understand the motivation better, consider that a user queries “saint mary school”. Now, the inverted index will provide us a list of documents containing the terms “saint”, “mary” and “school” independently. What we actually require, however, are documents where the entire phrase “saint mary school” appears verbatim. In order to successfully answer such queries, we require an index of documents that also stores the positions of terms.
Postings List
In the case of the inverted index, a postings list is a list of documents where the term appears. It is typically sorted by the document ID and stored in the form of a linked list.
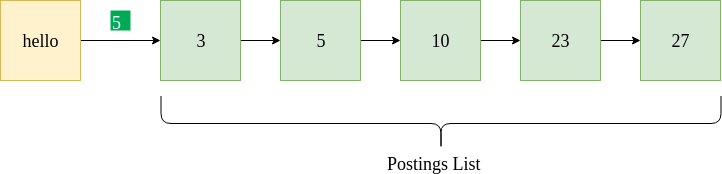
The above figure shows a sample postings list for the term “hello”. It indicates that “hello” appears in documents with docIDs 3, 5, 10, 23 and 27. It also specifies the document frequency 5 (highlighted in green). Given is a sample Python data format containing a dictionary and linked lists to store the postings list.
{"hello" : [5, [3, 5, 10, 23, 27] ] }
In the case of the positional index, the positions at which the term appears in a particular document is also stored along with the docID.
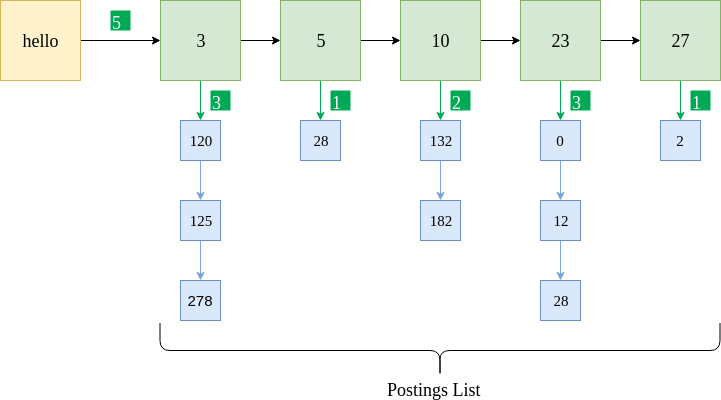
The above figure shows the same postings list implemented for a positional index. The blue boxes indicate the position of the term “hello” in the corresponding documents. For instance, “hello” appears in document 5 at three positions: 120, 125, and 278. Also, the frequency of the term is stored for each document. Given is a sample Python data format for the same.
{"hello" : [5, [ {3 : [3, [120, 125, 278]]}, {5 : [1, [28] ] }, {10 : [2, [132, 182]]}, {23 : [3, [0, 12, 28]]}, {27 : [1, [2]]} ] }
One can also omit the term frequency in the individual documents for the sake of simplicity (as done in the sample code). The data format then looks as follows.
{"hello" : [5, {3 : [120, 125, 278]}, {5 : [28]}, {10 : [132, 182]}, {23 : [0, 12, 28]}, {27 : [2]} ] }
Steps to build a Positional Index
- Fetch the document.
- Remove stop words, stem the resulting words.
- If the word is already present in the dictionary, add the document and the corresponding positions it appears in. Else, create a new entry.
- Also update the frequency of the word for each document, as well as the no. of documents it appears in.
Code
In order to implement a positional index, we make use of a sample dataset called “20 Newsgroups”.
Python3
import numpy as np
import os
import nltk
from nltk.stem import PorterStemmer
from nltk.tokenize import TweetTokenizer
from natsort import natsorted
import string
def read_file(filename):
with open(filename, 'r', encoding ="ascii", errors ="surrogateescape") as f:
stuff = f.read()
f.close()
stuff = remove_header_footer(stuff)
return stuff
def remove_header_footer(final_string):
new_final_string = ""
tokens = final_string.split('\n\n')
for token in tokens[1:-1]:
new_final_string += token+" "
return new_final_string
def preprocessing(final_string):
tokenizer = TweetTokenizer()
token_list = tokenizer.tokenize(final_string)
table = str.maketrans('', '', '\t')
token_list = [word.translate(table) for word in token_list]
punctuations = (string.punctuation).replace("'", "")
trans_table = str.maketrans('', '', punctuations)
stripped_words = [word.translate(trans_table) for word in token_list]
token_list = [str for str in stripped_words if str]
token_list =[word.lower() for word in token_list]
return token_list
folder_names = ["comp.graphics"]
stemmer = PorterStemmer()
fileno = 0
pos_index = {}
file_map = {}
for folder_name in folder_names:
file_names = natsorted(os.listdir("20_newsgroups/" + folder_name))
for file_name in file_names:
stuff = read_file("20_newsgroups/" + folder_name + "/" + file_name)
final_token_list = preprocessing(stuff)
for pos, term in enumerate(final_token_list):
term = stemmer.stem(term)
if term in pos_index:
pos_index[term][0] = pos_index[term][0] + 1
if fileno in pos_index[term][1]:
pos_index[term][1][fileno].append(pos)
else:
pos_index[term][1][fileno] = [pos]
else:
pos_index[term] = []
pos_index[term].append(1)
pos_index[term].append({})
pos_index[term][1][fileno] = [pos]
file_map[fileno] = "20_newsgroups/" + folder_name + "/" + file_name
fileno += 1
sample_pos_idx = pos_index["andrew"]
print("Positional Index")
print(sample_pos_idx)
file_list = sample_pos_idx[1]
print("Filename, [Positions]")
for fileno, positions in file_list.items():
print(file_map[fileno], positions)
|
Output:
Positional Index
[10, {215: [2081], 539: [66], 591: [879], 616: [462, 473], 680: [135], 691: [2081], 714: [4], 809: [333], 979: [0]}]
Filename, [Positions]
20_newsgroups/comp.graphics/38376 [2081]
20_newsgroups/comp.graphics/38701 [66]
20_newsgroups/comp.graphics/38753 [879]
20_newsgroups/comp.graphics/38778 [462, 473]
20_newsgroups/comp.graphics/38842 [135]
20_newsgroups/comp.graphics/38853 [2081]
20_newsgroups/comp.graphics/38876 [4]
20_newsgroups/comp.graphics/38971 [333]
20_newsgroups/comp.graphics/39663 [0]
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...