Python | Pandas Series.str.wrap()
Last Updated :
24 Sep, 2018
Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric Python packages. Pandas is one of those packages and makes importing and analyzing data much easier.
Pandas str.wrap() is an important method when dealing with long text data (Paragraphs or messages). This is used to distribute long text data into new lines or handle tab spaces when it exceeds the passed width. Since this is a string method, .str has to be prefixed every time before calling this method.
Syntax: Series.str.wrap(width, **kwargs)
Parameters:
width: Integer value, defines maximum line width
**kwargs[Optional parameters]
expand_tabs: Boolean value, expands tab characters to spaces if True
replace_whitespace: Boolean value, if true, each white space character is replaced by single white space.
drop_whitespace: Boolean value, If true, removes whitespace if any at the beginning of new lines
break_long_words: Boolean value, if True, breaks word that are longer than the passed width.
break_on_hyphens: Boolean value, if true, breaks string on hyphens where string length is less than width.
Return type: Series with splitted lines/added characters(‘\n’)
To download the data set used in code, click here.
In the following examples, the data frame used contains data of some NBA players. The image of data frame before any operations is attached below.
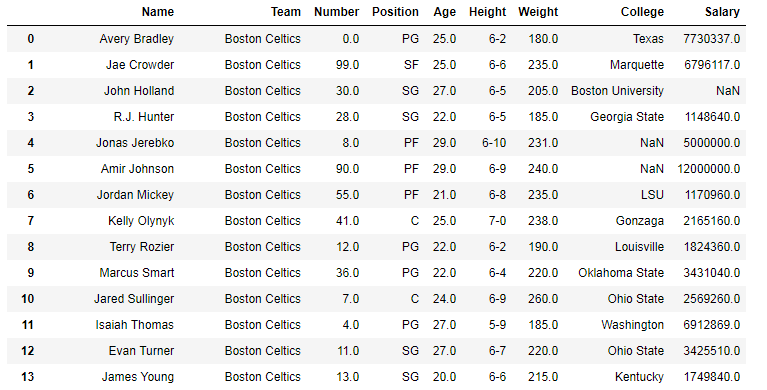
Example :
In this example, the Team column is wrapped with a line width of 5 characters. Hence \n will be put after every 5 character. A random element from new team column and old team column is printed to see the working. Before applying any operations, null elements are removed using .dropna() method.
import pandas as pd
data.dropna(inplace = True)
data["New Team"]= data["Team"].str.wrap(5)
data
print(data["Team"][120])
print("------------")
print(data["New Team"][120])
|
Output:
As shown in the output images, the New column has ‘\n’ after every 5 characters. After printing same index of old and New team columns, it can be seen that without adding new line character in print statement, python automatically read ‘\n’ in the string and put it in new line.
Data frame with New Team column-
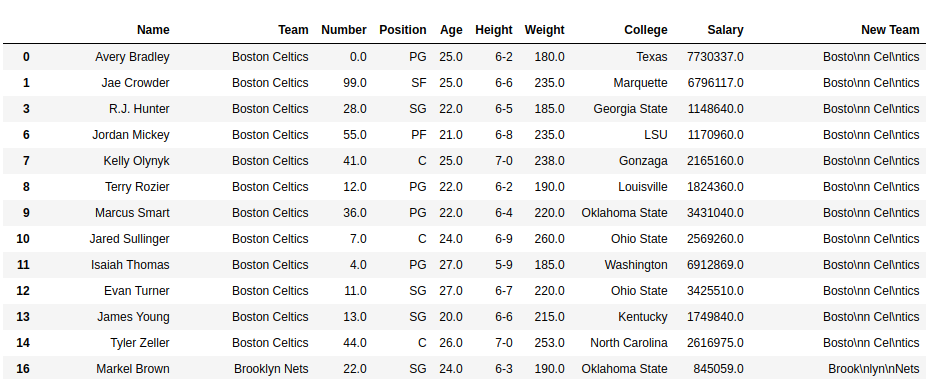
Output:
Los Angeles Lakers
------------
Los A
ngele
s Lak
ers
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...