Python | Pandas Series.str.slice()
Last Updated :
24 Sep, 2018
Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric python packages. Pandas is one of those packages and makes importing and analyzing data much easier.
Pandas str.slice() method is used to slice substrings from a string present in Pandas series object. It is very similar to Python’s basic principal of slicing objects that works on [start:stop:step] which means it requires three parameters, where to start, where to end and how much elements to skip.
Since this is a pandas string method, .str has to be prefixed every time before calling this method. Otherwise, it gives an error.
Syntax: Series.str.slice(start=None, stop=None, step=None)
Parameters:
start: int value, tells where to start slicing
stop: int value, tells where to end slicing
step: int value, tells how much characters to step during slicing
Return type: Series with sliced substrings
To download the CSV used in code, click here.
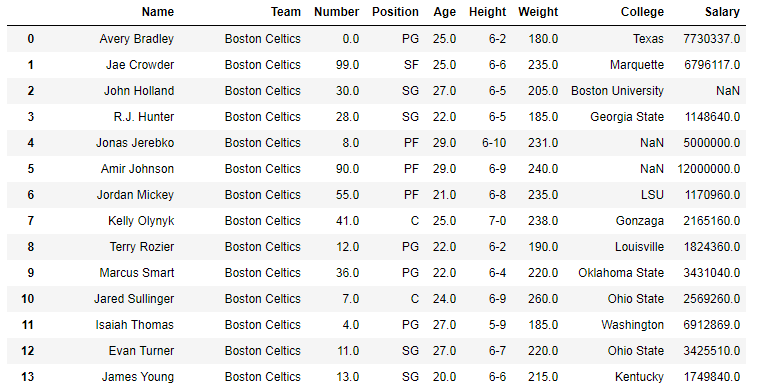
In the following examples, the data frame used contains data of some NBA players. The image of data frame before any operations is attached below.
Example #1:
In this example, the salary column has been sliced to get values before decimal. For example, we want to do some mathematical operations and for that we need integer data, so the salary column will be sliced till the 2nd last element(-2 position).
Since the salary column is imported as float64 data type, it is first converted to string using the .astype() method.
import pandas as pd
data.dropna(inplace = True)
start, stop, step = 0, -2, 1
data["Salary"]= data["Salary"].astype(str)
data["Salary (int)"]= data["Salary"].str.slice(start, stop, step)
data.head(10)
|
Output:
As shown in the output image, the string has been sliced and the string before decimal is stored in new column.

Note:This method doesn’t have any parameters to handle null values and hence they were already removed using .dropna() method.
Example #2:
In this example, the name column is sliced and step parameter is kept 2. Hence it will be stepping two characters during slicing.
import pandas as pd
data.dropna(inplace = True)
start, stop, step = 0, -2, 2
data["Name"]= data["Name"].str.slice(start, stop, step)
data.head(10)
|
Output:
As it can be seen in the output image, the Name was sliced and 2 characters were skipped during slicing.

Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...