Pandas DataFrame take() Method
Last Updated :
01 Feb, 2024
Python is a great tool for data analysis, primarily because of the fantastic ecosystem of data-centric Python packages like Pandas which make analyzing data much easier.
Pandas take() function returns elements on the given indices, along an axis. This means that we are not indexing according to actual values in the index attribute of the object. We are indexing according to the actual position of the element in the object.
Example:
Python3
import pandas as pd
import numpy as np
df = pd.DataFrame([
('eagle', 'bird', 320.0),
('sparrow', 'bird', 18.0),
('tiger', 'mammal', 80.5),
('monkey', 'mammal', np.nan)
], columns=['name', 'class', 'max_speed'], index=[0, 2, 3, 1])
df.take([0, 3])
|
Output:
name class max_speed
0 eagle bird 320.0
1 monkey mammal NaN
Syntax
Syntax: DataFrame.take(indices, axis=0, **kwargs)
Parameters
- indices: An array of ints indicating which positions to take.
- axis: The axis on which to select elements. 0 means that we are selecting rows, and 1 means that we are selecting columns
- **kwargs: Used for compatibility with numpy.take(). Does not affect the output.
Returns
- An array-like containing the elements taken from the object.
Download the sample CSV file here to practice DataFrame.take() method.
Examples
Let’s understand how to use take() method of the Pandas library to get elements in the given positional indices along an axis in a DataFrame.
Example 1: Use the DataFrame.take() function over the index(row) axis.
We will cover using DataFrame.take() the method keeping the axis parameter as “0”.
This will extract data row-wise from the DataFrame.
First, let’s create a DataFrame.
Python3
import pandas as pd
df = pd.read_csv("nba.csv")
df
|
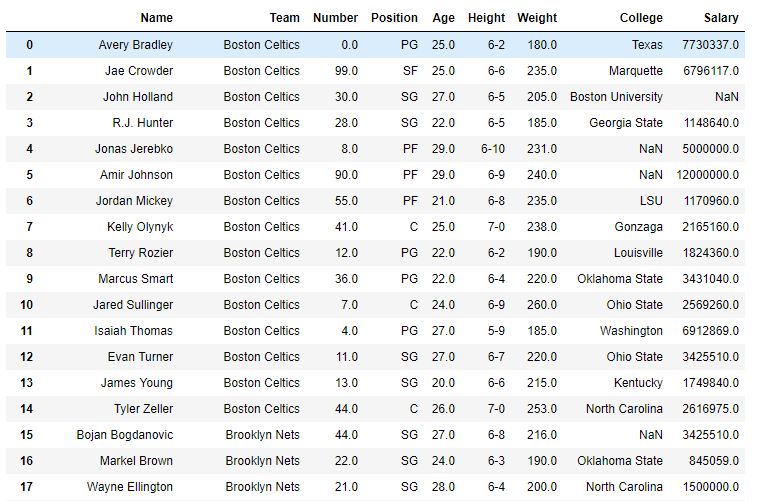
Now we will modify the index labels for demonstration purposes. Right now the labels are numbered from 0 to 914.
Python3
df.index = df.index * 2
df
|
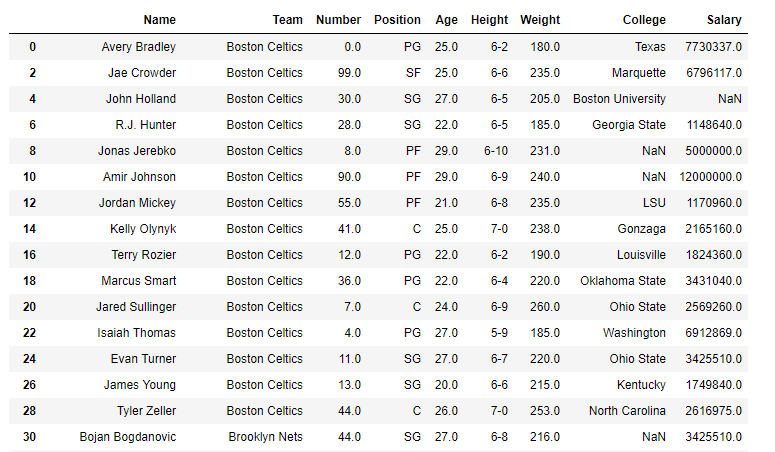
Let’s take the values at positions 0, 1, and 2 using DataFrame.take() function
Python3
df.take([0, 1, 2], axis = 0)
|
Output :

As we can see in the output, the values are selected based on the position but not on the index labels.
Example 2: Use the DataFrame.take() function over the column axis.
This will be very similar to Example 1, we just need to change axis parameter value to 1.
First, lets create a DataFrame
Python3
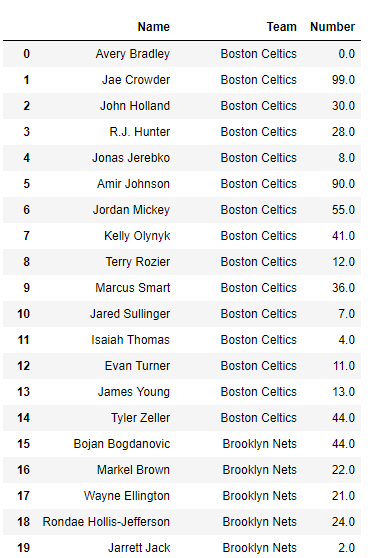
import pandas as pd
df = pd.read_csv("nba.csv")
df
|
Now we will take values at positions 0, 1, and 2 over the column axis.
Python3
df.take([0, 1, 2], axis = 1)
|
Output :
Conclusion
The DataFrame.take() method is a built-in function of the Pandas library in Python and is a very useful function used for data manipulation. It lets you extract specific data based on their position and returns a new DataFrame containing the extracted data.
This tutorial is made for the latest version of Python, teaching you how to use DataFrame.take() method. We have discussed the DataFrame.take() method with examples in easy language.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...