Python Convert Html to PDF
Last Updated :
30 Dec, 2017
Convert HTML/webpage to PDF
There are many websites that do not allow to download the content in form of pdf, they either ask to buy their premium version or don’t have such download service in form of pdf.
Conversion in 3 Steps from Webpage/HTML to PDF
Step1: Download library pdfkit
$ pip install pdfkit
Step2: Download wkhtmltopdf
For Ubuntu/Debian:
sudo apt-get install wkhtmltopdf
For Windows:
(a)Download link: WKHTMLTOPDF
(b)Set: PATH variable set binary folder in Environment variables.
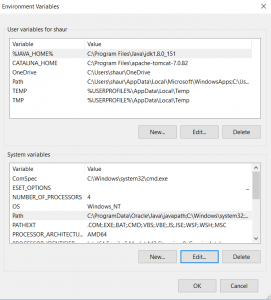
Step3: Code in Python to Download:
(i) Already Saved HTML page
import pdfkit
pdfkit.from_file('test.html', 'out.pdf')
|
(ii) Convert by website URL
(iii) Store text in PDF
import pdfkit
pdfkit.from_string('Shaurya GFG','GfG.pdf')
|
Congratulations: Your pdf file would be created and saved in the same directory where python file exists.
Miscellaneous Knowledge Content:
1. You can pass a list with multiple URLs or files:
pdfkit.from_url(['google.com', 'geeksforgeeks.org', 'facebook.com'], 'shaurya.pdf')
pdfkit.from_file(['file1.html', 'file2.html'], 'out.pdf')
|
2. Save content in a variable
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...