Python – Bamboolib for Pandas
Last Updated :
05 Sep, 2020
If you are a Data Science enthusiast or a Data Scientist you know that Pandas is an indispensable library that allows you to perform data wrangling, where you can read your data, preprocess your data, handle missing data etc. before building Machine Learning models.
Pandas sure does makes a lot of the work very easy and is very powerful but using it and mastering it can be a great challenge. To resolve this and make the use of pandas more convenient we have a library available in python which is called the Bamboolib library.
Bamboolib: It is a GUI extension for pandas data-frames for easy data exploration and transformation that enables anyone to work with Python in Jupyter Notebook or JupyterLab.
Let us have a look at some of the functionalities of this library and how to use them.
Note: Bamboolib is available for free only on Kaggle and Binder for open data. You can use the paid version on your computer as well.
Installation of Bamboolib library:
Before getting started we need to install the library first. Follow these steps to install the library correctly.
#install bamboolib on linux or anaconda prompt
pip install bamboolib
- If you want to use the library on Kaggle or Binder you can stop at this step, else continue-
After the installation is complete run the following commands:
jupyter nbextension enable --py qgrid --sys-prefix
jupyter nbextension enable --py widgetsnbextension --sys-prefix
jupyter nbextension install --py bamboolib --sys-prefix
jupyter nbextension enable --py bamboolib --sys-prefix
If you want to use this on Jupyter notebook then you can stop here but if you want to use this on JupyterLab as well you can continue following the steps to complete the installation.
Make sure you have node.js and npm installed.
#install nodejs on anaconda prompt
conda install -c conda-forge nodejs
#install npm on anaconda prompt
pip install npm
Next run these commands:
jupyter labextension install @jupyter-widgets/jupyterlab-manager --no-build
jupyter labextension install @8080labs/qgrid --no-build
jupyter labextension install plotlywidget --no-build
jupyter labextension install jupyterlab-plotly --no-build
jupyter labextension install bamboolib --no-build
jupyter lab build --minimize=False
Now the installation is complete.
How to use Bamboolib:
To see how to use this library we are going to use Binder.For this browse to github. You can also build your own Binder notebook by following the steps mentioned or use the already available notebook like we will be doing here.
After your notebook opens up run the below code to visualize the data:
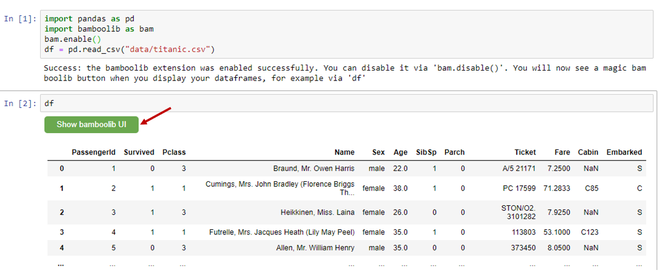
Now you can use the Show bamboolib UI button to perform various functions.
You can see mainly 3 options available:
- Explore DataFrame
- Create Plot
- Search for transformation
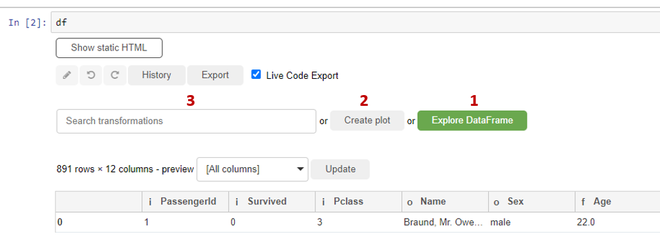
1) Explore DataFrame:
You have 4 options available, namely:
- Glimpse: In this you get information about the columns in the dataset. You can know about the data type of the column, number of unique values, missing values in a column out of ‘n’ rows, here n=891.

- Columns: This provides information of each column.The overview of a particular column, categoric overview– number of times a particular value has appeared in the column.

This also provides Bivariate plots between two columns to gain more information about the dataset.

- Predictor Patterns: You can predict the patterns of the dataset by clicking on any cell of the heatmap to get the relation between the columns.

- Correlation Matrix: You can get the correlation matrix between any of the columns.

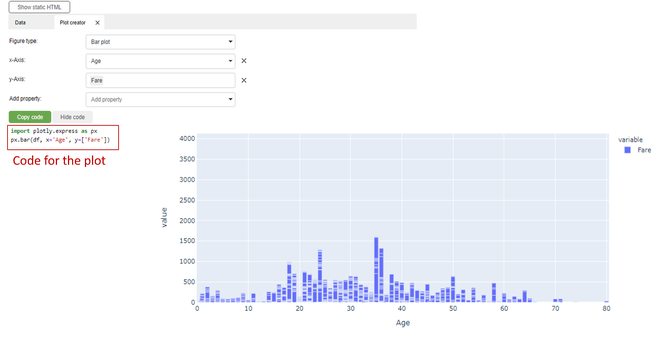
2) Create Plot:
You can create any plot like bar plot, histogram, scatter plot etc. and can add different properties. The pandas’ code for developing the plot is also available which you can copy and paste as well to get the same output.
3) Search for Transformation:
You can perform various transformations on the dataset. Some of the few are:
Drop Column: Since in the dataset used we can see that Cabin has a high number of missing values so we can remove/drop this column from the dataset. Choose the Select or Drop columns option, fill the fields and press Execute.
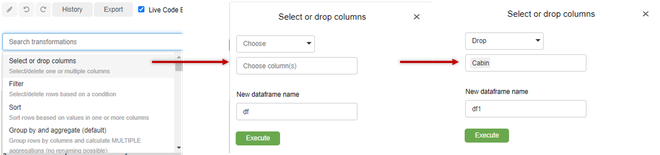
You get the pandas code automatically and is executed for this transformation that you have performed.The new dataframe is displayed as output.

Filter: Using this option you can create subsets of data to analyze it applying certain conditions.This is the most used technique to get meaningful insights in the data.Here we have filtered the dataset on the ‘Age’ column to access the records with Age>25.

New dataframe is displayed as output.
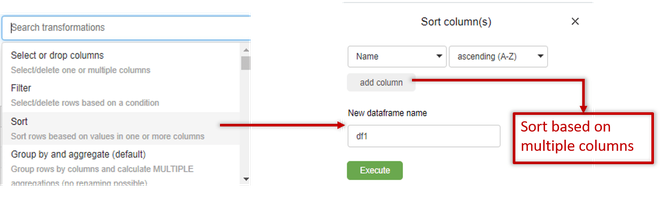
Sort: You can sort your dataset on columns using this transformation.Sorting can also be performed for multiple columns simultaneously.Here we have sorted the data on the ‘Name’ column in ascending order.
Note:
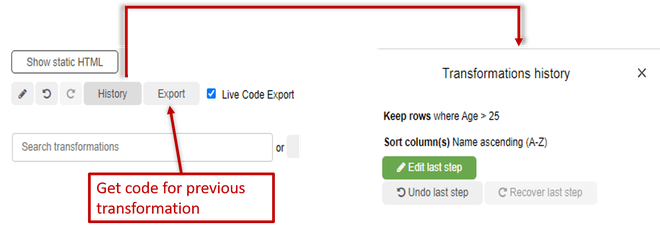
- To undo or redo any transformation you have performed on the dataframe you can click on the History button.
- To get the code of previous transformation go to Export. If Live Code Export is checked then you’ll get the code automatically.
Bamboolib offers many other transformation options such as Group by and aggregate, Rename columns, Replace Value, Change column datatypes etc.
Benefits of using Bamboolib:
Bamboolib is a very handy and easy to use.Transformations of huge data-frameworks can be performed in no time.It is great for organizations as employees with little programming knowledge can also use this tool without struggling or looking up for the syntax to get the task done and can get the syntax for the operation or transformation afterwards.This is also helpful for programmers as they can play around with data and study the syntax for the user specific problem instead of looking up for different cases and trying to extract the required result.
Now that you have learned this amazing hands-on tool, give it a try for yourself and explore the hidden information your data can provide. For any queries do leave a comment down below.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...