PySpark – Create DataFrame from List
Last Updated :
30 May, 2021
In this article, we are going to discuss how to create a Pyspark dataframe from a list.
To do this first create a list of data and a list of column names. Then pass this zipped data to spark.createDataFrame() method. This method is used to create DataFrame. The data attribute will be the list of data and the columns attribute will be the list of names.
dataframe = spark.createDataFrame(data, columns)
Example1: Python code to create Pyspark student dataframe from two lists.
Python3
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
data = [["java", "dbms", "python"],
["OOPS", "SQL", "Machine Learning"]]
columns = ["Subject 1", "Subject 2", "Subject 3"]
dataframe = spark.createDataFrame(data, columns)
dataframe.show()
|
Output:
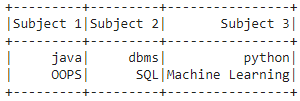
Example 2: Create a dataframe from 4 lists
Python3
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
data = [["node.js", "dbms", "integration"],
["jsp", "SQL", "trigonometry"],
["php", "oracle", "statistics"],
[".net", "db2", "Machine Learning"]]
columns = ["Web Technologies", "Data bases", "Maths"]
dataframe = spark.createDataFrame(data, columns)
dataframe.show()
|
Output:

Share your thoughts in the comments
Please Login to comment...