Practice Questions on Huffman Encoding
Last Updated :
06 Feb, 2018
Huffman Encoding is an important topic from GATE point of view and different types of questions are asked from this topic. Before understanding this article, you should have basic idea about Huffman encoding.
These are the types of questions asked in GATE based on Huffman Encoding.
Type 1. Conceptual questions based on Huffman Encoding –
Here are the few key points based on Huffman Encoding:
- It is a lossless data compressing technique generating variable length codes for different symbols.
- It is based on greedy approach which considers frequency/probability of alphabets for generating codes.
- It has complexity of nlogn where n is the number of unique characters.
- The length of the code for a character is inversely proportional to frequency of its occurrence.
- No code is prefix of another code due to which a sequence of code can be unambiguously decoded to characters.
Que – 1. Which of the following is true about Huffman Coding?
(A) Huffman coding may become lossy in some cases
(B) Huffman Codes may not be optimal lossless codes in some cases
(C) In Huffman coding, no code is prefix of any other code.
(D) All of the above
Solution: As discussed, Huffman encoding is a lossless compression technique. Therefore, option (A) and (B) are false. Option (C) is true as this is the basis of decoding of message from given code.
Type 2. To find number of bits for encoding a given message –
To solve this type of questions:
- First calculate frequency of characters if not given
- Generate Huffman Tree
- Calculate number of bits using frequency of characters and number of bits required to represent those characters.
Que – 2. How many bits may be required for encoding the message ‘mississippi’?
Solution: Following is the frequency table of characters in ‘mississippi’ in non-decreasing order of frequency:

The generated Huffman tree is:
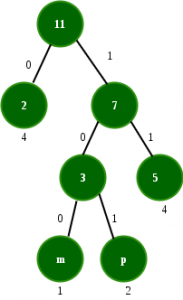
Following are the codes:
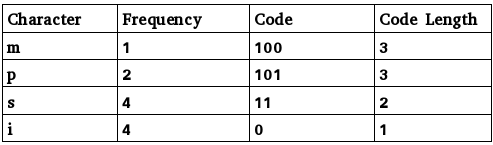
Total number of bits
= freq(m) * codelength(m) + freq(p) * code_length(p) + freq(s) * code_length(s) + freq(i) * code length(i)
= 1*3 + 2*3 + 4*2 + 4*1 = 21
Also, average bits per character can be found as:
Total number of bits required / total number of characters = 21/11 = 1.909
Type 3. Decoding from code to message –
To solve this type of question:
- Generate codes for each character using Huffman tree (if not given)
- Using prefix matching, replace the codes with characters.
Que – 3. The characters a to h have the set of frequencies based on the first 8 Fibonacci numbers as follows:
a : 1, b : 1, c : 2, d : 3, e : 5, f : 8, g : 13, h : 21
A Huffman code is used to represent the characters. What is the sequence of characters corresponding to the following code?
110111100111010
(A) fdheg
(B) ecgdf
(C) dchfg
(D) fehdg
Solution: Using frequencies given in the question, huffman tree can be generated as:
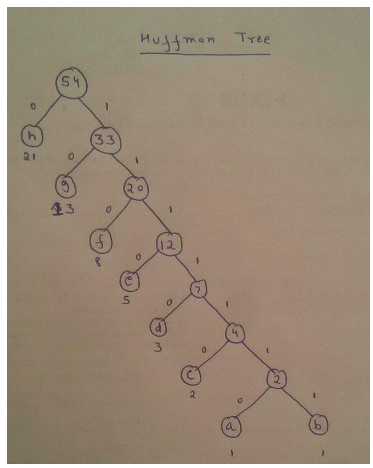
Following are the codes:

Using prefix matching, given string can be decomposed as
110 11110 0 1110 10
f d h e g
Type 4. Number of bits saved using Huffman encoding –
Que – 4. A networking company uses a compression technique to encode the message before transmitting over the network. Suppose the message contains the following characters with their frequency:

Note that each character in input message takes 1 byte.
If the compression technique used is Huffman Coding, how many bits will be saved in the message?
(A) 224
(B) 800
(C) 576
(D) 324
Solutions: Finding number of bits without using Huffman,
Total number of characters = sum of frequencies = 100
size of 1 character = 1byte = 8 bits
Total number of bits = 8*100 = 800
Using Huffman Encoding, Total number of bits needed can be calculated as:
5*4 + 9*4 + 12*3 + 13*3 + 16*3 + 45* 1 = 224
Bits saved = 800-224 = 576.

Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...