PostgreSQL – Trigger
Last Updated :
28 Aug, 2020
A PostgreSQL trigger is a function invoked automatically whenever an event associated with a table occurs. An event could be any of the following: INSERT, UPDATE, DELETE or TRUNCATE.
A trigger is a special user-defined function associated with a table. To create a new trigger, you must define a trigger function first, and then bind this trigger function to a table. The difference between a trigger and a user-defined function is that a trigger is automatically invoked when an event occurs.
PostgreSQL provides two main types of triggers:
- Row level-triggers
- Statement-level triggers
The differences between the two kinds are how many times the trigger is invoked and at what time. For example, if you issue an UPDATE statement that affects 20 rows, the row-level trigger will be invoked 20 times, while the statement level trigger will be invoked 1 time.
You can specify whether the trigger is invoked before or after an event. If the trigger is invoked before an event, it can skip the operation for the current row or even change the row being updated or inserted. In case the trigger is invoked after the event, all changes are available to the trigger.
Triggers are useful in case the database is accessed by various applications, and you want to keep the cross-functionality within the database that runs automatically whenever the data of the table is modified. For example, if you want to keep the history of data without requiring the application to have logic to check for every event such as INSERT or UPDATE.
You can also use triggers to maintain complex data integrity rules which you cannot implement elsewhere except at the database level. For example, when a new row is added into the customer table, other rows must be also created in tables of banks and credits.
The main drawback of using a trigger is that you must know the trigger exists and understand its logic to figure it out the effects when data changes.
Even though PostgreSQL implements SQL standard, triggers in PostgreSQL has some specific features as follows:
- PostgreSQL fires trigger for the TRUNCATE event.
- PostgreSQL allows you to define the statement-level trigger on views.
- PostgreSQL requires you to define a user-defined function as the action of the trigger, while the SQL standard allows you to use any number of SQL commands.
Example:
Let’s take a look at an example of creating a new trigger. In this example, we will create a new table named employees as follows:
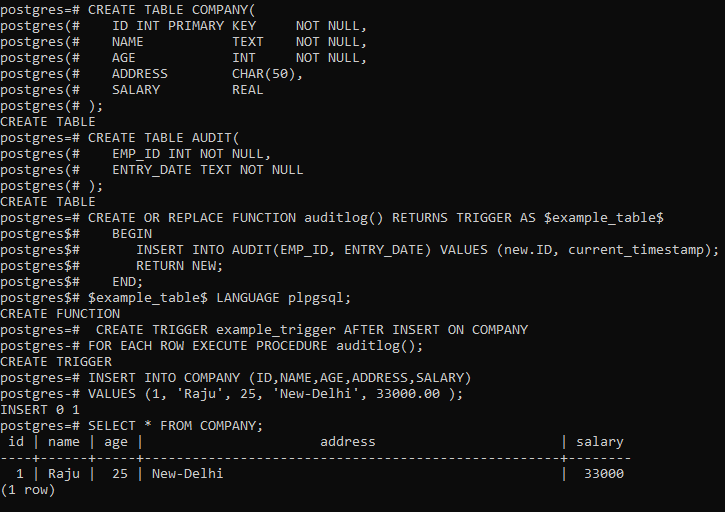
CREATE TABLE COMPANY(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
When the name of an employee changes, we log the changes in a separate table named employee_audits :
CREATE TABLE AUDIT(
EMP_ID INT NOT NULL,
ENTRY_DATE TEXT NOT NULL
);
First, define a new function called auditlog():
CREATE OR REPLACE FUNCTION auditlog() RETURNS TRIGGER AS $example_table$
BEGIN
INSERT INTO AUDIT(EMP_ID, ENTRY_DATE) VALUES (new.ID, current_timestamp);
RETURN NEW;
END;
$example_table$ LANGUAGE plpgsql;
The function inserts the old last name into the employee_audits table including employee id, last name, and the time of change if the last name of an employee changes. Second, bind the trigger function to the employees table. The trigger name is last_name_changes. Before the value of the last_name column is updated, the trigger function is automatically invoked to log the changes.
CREATE TRIGGER example_trigger AFTER INSERT ON COMPANY
FOR EACH ROW EXECUTE PROCEDURE auditlog();
Third, insert some sample data for testing. We insert two rows into the employees table.
INSERT INTO COMPANY (ID, NAME, AGE, ADDRESS, SALARY)
VALUES (1, 'Raju', 25, 'New-Delhi', 33000.00 );
To examine the employees table use the below query:
SELECT * FROM COMPANY;
Output:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...