Pipelining in ARM
Last Updated :
18 Jun, 2021
ARM Pipelining :
- A Pipelining is the mechanism used by RISC(Reduced instruction set computer) processors to execute instructions,
- by speeding up the execution by fetching the instruction, while other instructions are being decoded and executed simultaneously.
- Which in turn allows the memory system and processor to work continuously.
- The pipeline design for each ARM family is different.
Pipelining is a design technique or a process which plays an important role in increasing the efficiency of data processing in the processor of a computer and microcontroller. By keeping the processor in a continuous process of fetching, decoding and executing called (F&E cycle).
ARM devices need pipelining because of RISC as it emphasizes on compiler complexity. Each stage is equivalent to 1 cycle, that is n stages = n cycles.
Pipeline :
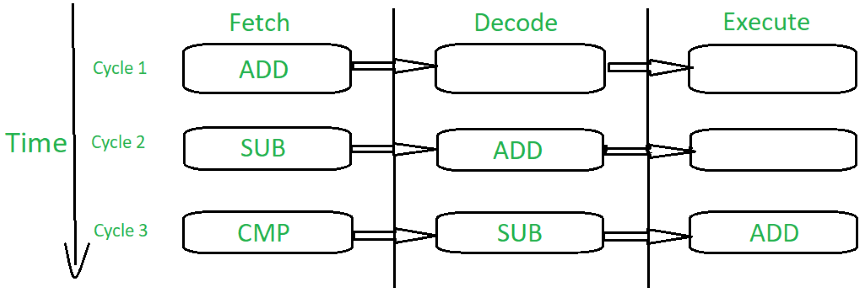
3 stage pipelining
- Fetch loads an instruction from memory.
- Decode identifies the instruction to be executed.
- Execute processes the instruction and writes the result back to the register.
- By over lapping the above stages of execution of different instructions, the speed of execution is increased.
- The pipelining allows the core to execute an instruction every cycle, which results in increased throughput.
ARM pipeline characteristics :
- The ARM pipeline doesn’t process an instruction until it passes completely through the execution stage.
- In the execution stage, the PC always points to the instruction address + 8 bytes.
- When the processor is in thumb state, PC always points to the instruction address + 4 bytes.
- While executing branch instructions or branching by direct modification of PC causes the ARM core to flush it’s pipeline.
- As instruction in the execution stage will complete its execution even though an interrupt has been raised.
ARM 7 –
- It has 3 stage pipelining as shown in the figure.
- It can complete it’s process in 3 cycles.
- It has the basic F&E cycle leading to optimum throughput.
- This is why the ARM 7 has the lowest throughput as compared to that of it’s other family members.
- It processes 32bit data.
ARM 9 –
- Pipelining in ARM 9 is similar to ARM 7 but with 5 stages.
- It takes 5 cycles to complete the process.

5 stage pipelining
- Fetch- It will fetch instructions from memory.
- Decode- It decodes the instructions that were fetched in the first cycle.
- ALU – It executes the instruction that has been decoded in the previous stage.
- LS1(Memory) Loads/Stores the data specified by load or store instructions.
- LS2(Write) Extracts (zero or sign) extends the data loaded by byte or half word load instruction.
- Because of an increase in stages and efficiency, the throughput is 10%-13% higher than ARM 7.
- Core frequency of ARM 9 is slightly higher than that of ARM 7.
ARM 10 –
- It is a six stage pipeline. Which in turn takes 6 cycles to complete the process.
- Same as that of ARM 9 but with an issue stage which checks whether the instruction is ready to get decoded in the current stage or not.
- It nearly doubles the throughput than that of ARM 7.
- The core frequency is higher than that of ARM 9.

6 stage pipelining
The stages of pipelining may increase or decrease on the basis of the instruction sets processed per cycle (In maximum situations, stages tend to increase to increase efficiency).
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...