Peterson’s Algorithm for Mutual Exclusion | Set 2 (CPU Cycles and Memory Fence)
Last Updated :
18 Apr, 2024
Problem: Given 2 process i and j, you need to write a program that can guarantee mutual exclusion between the two without any additional hardware support.
We strongly recommend to refer below basic solution discussed in previous article.
Peterson’s Algorithm for Mutual Exclusion | Set 1
We would be resolving 2 issues in the previous algorithm.
Wastage of CPU clock cycles
In layman terms, when a thread was waiting for its turn, it ended in a long while loop which tested the condition millions of times per second thus doing unnecessary computation. There is a better way to wait, and it is known as “yield”.
To understand what it does, we need to dig deep into how the Process scheduler works in Linux. The idea mentioned here is a simplified version of the scheduler, the actual implementation has lots of complications.
Consider the following example,
There are three processes, P1, P2 and P3. Process P3 is such that it has a while loop similar to the one in our code, doing not so useful computation, and it exists from the loop only when P2 finishes its execution. The scheduler puts all of them in a round robin queue. Now, say the clock speed of processor is 1000000/sec, and it allocates 100 clocks to each process in each iteration. Then, first P1 will be run for 100 clocks (0.0001 seconds), then P2(0.0001 seconds) followed by P3(0.0001 seconds), now since there are no more processes, this cycle repeats until P2 ends and then followed by P3’s execution and eventually its termination.
This is a complete waste of the 100 CPU clock cycles. To avoid this, we mutually give up the CPU time slice, i.e. yield, which essentially ends this time slice and the scheduler picks up the next process to run. Now, we test our condition once, then we give up the CPU. Considering our test takes 25 clock cycles, we save 75% of our computation in a time slice. To put this graphically,
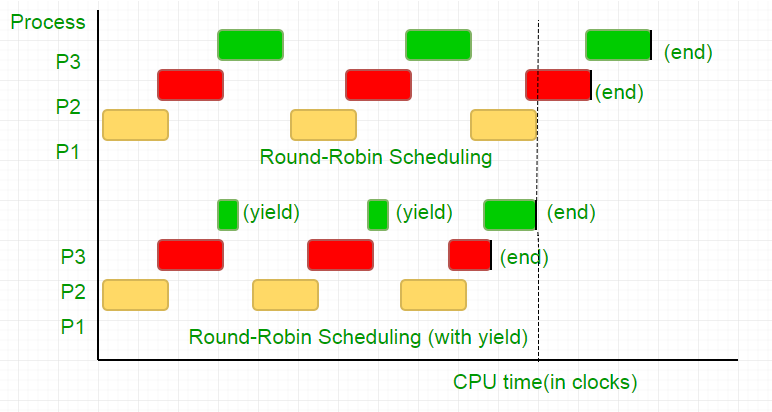
Considering the processor clock speed as 1MHz this is a lot of saving!.
Different distributions provide different function to achieve this functionality. Linux provides sched_yield().
C
void lock(int self)
{
flag[self] = 1;
turn = 1-self;
while (flag[1-self] == 1 &&
turn == 1-self)
// Only change is the addition of
// sched_yield() call
sched_yield();
}
Memory fence.
The code in earlier tutorial might have worked on most systems, but is was not 100% correct. The logic was perfect, but most modern CPUs employ performance optimizations that can result in out-of-order execution. This reordering of memory operations (loads and stores) normally goes unnoticed within a single thread of execution, but can cause unpredictable behaviour in concurrent programs.
Consider this example,
C
while (f == 0);
// Memory fence required here
print x;
In the above example, the compiler considers the 2 statements as independent of each other and thus tries to increase the code efficiency by re-ordering them, which can lead to problems for concurrent programs. To avoid this we place a memory fence to give hint to the compiler about the possible relationship between the statements across the barrier.
So the order of statements,
flag[self] = 1;
turn = 1-self;
while (turn condition check)
yield();
has to be exactly the same in order for the lock to work, otherwise it will end up in a deadlock condition.
To ensure this, compilers provide a instruction that prevent ordering of statements across this barrier. In case of gcc, its __sync_synchronize().
So the modified code becomes,
Full Implementation in C:
C++
// Filename: peterson_yieldlock_memoryfence.cpp
// Use below command to compile:
// g++ -pthread peterson_yieldlock_memoryfence.cpp -o peterson_yieldlock_memoryfence
#include<iostream>
#include<thread>
#include<atomic>
std::atomic<int> flag[2];
std::atomic<int> turn;
const int MAX = 1e9;
int ans = 0;
void lock_init()
{
// Initialize lock by resetting the desire of
// both the threads to acquire the locks.
// And, giving turn to one of them.
flag[0] = flag[1] = 0;
turn = 0;
}
// Executed before entering critical section
void lock(int self)
{
// Set flag[self] = 1 saying you want
// to acquire lock
flag[self]=1;
// But, first give the other thread the
// chance to acquire lock
turn = 1-self;
// Memory fence to prevent the reordering
// of instructions beyond this barrier.
std::atomic_thread_fence(std::memory_order_seq_cst);
// Wait until the other thread loses the
// desire to acquire lock or it is your
// turn to get the lock.
while (flag[1-self]==1 && turn==1-self)
// Yield to avoid wastage of resources.
std::this_thread::yield();
}
// Executed after leaving critical section
void unlock(int self)
{
// You do not desire to acquire lock in future.
// This will allow the other thread to acquire
// the lock.
flag[self]=0;
}
// A Sample function run by two threads created
// in main()
void func(int s)
{
int i = 0;
int self = s;
std::cout << "Thread Entered: " << self << std::endl;
lock(self);
// Critical section (Only one thread
// can enter here at a time)
for (i=0; i<MAX; i++)
ans++;
unlock(self);
}
// Driver code
int main()
{
// Initialize the lock
lock_init();
// Create two threads (both run func)
std::thread t1(func, 0);
std::thread t2(func, 1);
// Wait for the threads to end.
t1.join();
t2.join();
std::cout << "Actual Count: " << ans << " | Expected Count: " << MAX*2 << std::endl;
return 0;
}
// Filename: peterson_yieldlock_memoryfence.c
// Use below command to compile:
// gcc -pthread peterson_yieldlock_memoryfence.c -o peterson_yieldlock_memoryfence
#include<stdio.h>
#include<pthread.h>
#include "mythreads.h"
int flag[2];
int turn;
const int MAX = 1e9;
int ans = 0;
void lock_init()
{
// Initialize lock by resetting the desire of
// both the threads to acquire the locks.
// And, giving turn to one of them.
flag[0] = flag[1] = 0;
turn = 0;
}
// Executed before entering critical section
void lock(int self)
{
// Set flag[self] = 1 saying you want
// to acquire lock
flag[self]=1;
// But, first give the other thread the
// chance to acquire lock
turn = 1-self;
// Memory fence to prevent the reordering
// of instructions beyond this barrier.
__sync_synchronize();
// Wait until the other thread loses the
// desire to acquire lock or it is your
// turn to get the lock.
while (flag[1-self]==1 && turn==1-self)
// Yield to avoid wastage of resources.
sched_yield();
}
// Executed after leaving critical section
void unlock(int self)
{
// You do not desire to acquire lock in future.
// This will allow the other thread to acquire
// the lock.
flag[self]=0;
}
// A Sample function run by two threads created
// in main()
void* func(void *s)
{
int i = 0;
int self = (int *)s;
printf("Thread Entered: %d\n",self);
lock(self);
// Critical section (Only one thread
// can enter here at a time)
for (i=0; i<MAX; i++)
ans++;
unlock(self);
}
// Driver code
int main()
{
pthread_t p1, p2;
// Initialize the lock
lock_init();
// Create two threads (both run func)
Pthread_create(&p1, NULL, func, (void*)0);
Pthread_create(&p2, NULL, func, (void*)1);
// Wait for the threads to end.
Pthread_join(p1, NULL);
Pthread_join(p2, NULL);
printf("Actual Count: %d | Expected Count:"
" %d\n",ans,MAX*2);
return 0;
}
import java.util.concurrent.atomic.AtomicInteger;
public class PetersonYieldLockMemoryFence {
static AtomicInteger[] flag = new AtomicInteger[2];
static AtomicInteger turn = new AtomicInteger();
static final int MAX = 1000000000;
static int ans = 0;
static void lockInit() {
flag[0] = new AtomicInteger();
flag[1] = new AtomicInteger();
flag[0].set(0);
flag[1].set(0);
turn.set(0);
}
static void lock(int self) {
flag[self].set(1);
turn.set(1 - self);
// Memory fence to prevent the reordering of instructions beyond this barrier.
// In Java, volatile variables provide this guarantee implicitly.
// No direct equivalent to atomic_thread_fence is needed.
while (flag[1 - self].get() == 1 && turn.get() == 1 - self)
Thread.yield();
}
static void unlock(int self) {
flag[self].set(0);
}
static void func(int s) {
int i = 0;
int self = s;
System.out.println("Thread Entered: " + self);
lock(self);
// Critical section (Only one thread can enter here at a time)
for (i = 0; i < MAX; i++)
ans++;
unlock(self);
}
public static void main(String[] args) {
// Initialize the lock
lockInit();
// Create two threads (both run func)
Thread t1 = new Thread(() -> func(0));
Thread t2 = new Thread(() -> func(1));
// Start the threads
t1.start();
t2.start();
try {
// Wait for the threads to end.
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Actual Count: " + ans + " | Expected Count: " + MAX * 2);
}
}
import threading
flag = [0, 0]
turn = 0
MAX = 10**9
ans = 0
def lock_init():
# This function initializes the lock by resetting the flags and turn.
global flag, turn
flag = [0, 0]
turn = 0
def lock(self):
# This function is executed before entering the critical section. It sets the flag for the current thread and gives the turn to the other thread.
global flag, turn
flag[self] = 1
turn = 1 - self
while flag[1-self] == 1 and turn == 1-self:
pass
def unlock(self):
# This function is executed after leaving the critical section. It resets the flag for the current thread.
global flag
flag[self] = 0
def func(s):
# This function is executed by each thread. It locks the critical section, increments the shared variable, and then unlocks the critical section.
global ans
self = s
print(f"Thread Entered: {self}")
lock(self)
for _ in range(MAX):
ans += 1
unlock(self)
def main():
# This is the main function where the threads are created and started.
lock_init()
t1 = threading.Thread(target=func, args=(0,))
t2 = threading.Thread(target=func, args=(1,))
t1.start()
t2.start()
t1.join()
t2.join()
print(f"Actual Count: {ans} | Expected Count: {MAX*2}")
if __name__ == "__main__":
main()
// mythread.h (A wrapper header file with assert statements)
#ifndef __MYTHREADS_h__
#define __MYTHREADS_h__
#include <pthread.h>
#include <cassert>
#include <sched.h>
// Function to lock a pthread mutex
void Pthread_mutex_lock(pthread_mutex_t *m)
{
int rc = pthread_mutex_lock(m);
assert(rc == 0); // Assert that the mutex was locked successfully
}
// Function to unlock a pthread mutex
void Pthread_mutex_unlock(pthread_mutex_t *m)
{
int rc = pthread_mutex_unlock(m);
assert(rc == 0); // Assert that the mutex was unlocked successfully
}
// Function to create a pthread
void Pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine)(void*), void *arg)
{
int rc = pthread_create(thread, attr, start_routine, arg);
assert(rc == 0); // Assert that the thread was created successfully
}
// Function to join a pthread
void Pthread_join(pthread_t thread, void **value_ptr)
{
int rc = pthread_join(thread, value_ptr);
assert(rc == 0); // Assert that the thread was joined successfully
}
#endif // __MYTHREADS_h__
// mythread.h (A wrapper header file with assert
// statements)
#ifndef __MYTHREADS_h__
#define __MYTHREADS_h__
#include <pthread.h>
#include <assert.h>
#include <sched.h>
void Pthread_mutex_lock(pthread_mutex_t *m)
{
int rc = pthread_mutex_lock(m);
assert(rc == 0);
}
void Pthread_mutex_unlock(pthread_mutex_t *m)
{
int rc = pthread_mutex_unlock(m);
assert(rc == 0);
}
void Pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine)(void*), void *arg)
{
int rc = pthread_create(thread, attr, start_routine, arg);
assert(rc == 0);
}
void Pthread_join(pthread_t thread, void **value_ptr)
{
int rc = pthread_join(thread, value_ptr);
assert(rc == 0);
}
#endif // __MYTHREADS_h__
import threading
import ctypes
# Function to lock a thread lock
def Thread_lock(lock):
lock.acquire() # Acquire the lock
# No need for assert in Python, acquire will raise an exception if it fails
# Function to unlock a thread lock
def Thread_unlock(lock):
lock.release() # Release the lock
# No need for assert in Python, release will raise an exception if it fails
# Function to create a thread
def Thread_create(target, args=()):
thread = threading.Thread(target=target, args=args)
thread.start() # Start the thread
# No need for assert in Python, thread.start() will raise an exception if it fails
# Function to join a thread
def Thread_join(thread):
thread.join() # Wait for the thread to finish
# No need for assert in Python, thread.join() will raise an exception if it fails
Output:
Thread Entered: 1
Thread Entered: 0
Actual Count: 2000000000 | Expected Count: 2000000000
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...