Pattern Searching using a Trie of all Suffixes
Last Updated :
20 Feb, 2023
Problem Statement: Given a text txt[0..n-1] and a pattern pat[0..m-1], write a function search(char pat[], char txt[]) that prints all occurrences of pat[] in txt[]. You may assume that n > m.
As discussed in the previous post, we discussed that there are two ways efficiently solve the above problem.
1) Preprocess Pattern: KMP Algorithm, Rabin Karp Algorithm, Finite Automata, Boyer Moore Algorithm.
2) Preprocess Text: Suffix Tree
The best possible time complexity achieved by first (preprocessing pattern) is O(n) and by second (preprocessing text) is O(m) where m and n are lengths of pattern and text respectively.
Note that the second way does the searching only in O(m) time and it is preferred when text doesn’t change very frequently and there are many search queries. We have discussed Suffix Tree (A compressed Trie of all suffixes of Text) .
Implementation of Suffix Tree may be time consuming for problems to be coded in a technical interview or programming contexts. In this post simple implementation of a Standard Trie of all Suffixes is discussed. The implementation is close to suffix tree, the only thing is, it’s a simple Trie instead of compressed Trie.
As discussed in Suffix Tree post, the idea is, every pattern that is present in text (or we can say every substring of text) must be a prefix of one of all possible suffixes. So if we build a Trie of all suffixes, we can find the pattern in O(m) time where m is pattern length.
Building a Trie of Suffixes
1) Generate all suffixes of given text.
2) Consider all suffixes as individual words and build a trie.
Let us consider an example text “banana\0” where ‘\0’ is string termination character. Following are all suffixes of “banana\0”
banana\0
anana\0
nana\0
ana\0
na\0
a\0
\0
If we consider all of the above suffixes as individual words and build a Trie, we get following.
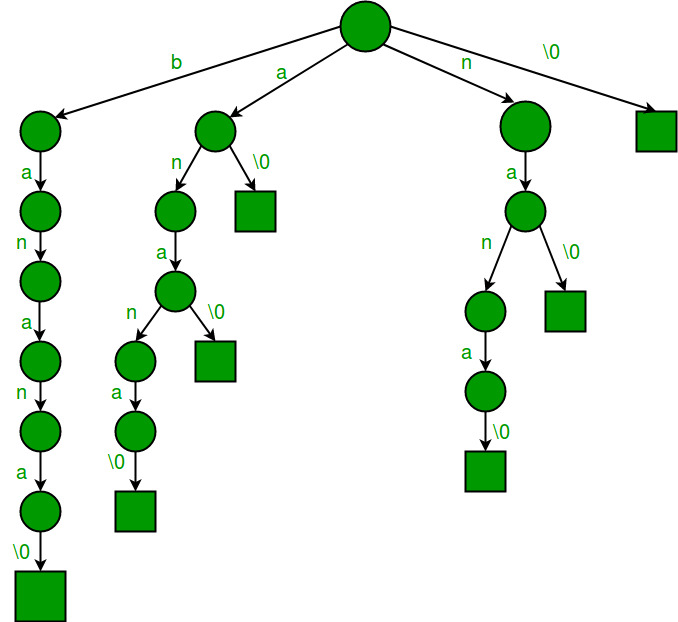
How to search a pattern in the built Trie?
Following are steps to search a pattern in the built Trie.
1) Starting from the first character of the pattern and root of the Trie, do following for every character.
…..a) For the current character of pattern, if there is an edge from the current node, follow the edge.
…..b) If there is no edge, print “pattern doesn’t exist in text” and return.
2) If all characters of pattern have been processed, i.e., there is a path from root for characters of the given pattern, then print all indexes where pattern is present. To store indexes, we use a list with every node that stores indexes of suffixes starting at the node.
Following is the implementation of the above idea.
C++
#include<iostream>
#include<list>
#define MAX_CHAR 256
using namespace std;
class SuffixTrieNode
{
private:
SuffixTrieNode *children[MAX_CHAR];
list<int> *indexes;
public:
SuffixTrieNode()
{
indexes = new list<int>;
for (int i = 0; i < MAX_CHAR; i++)
children[i] = NULL;
}
void insertSuffix(string suffix, int index);
list<int>* search(string pat);
};
class SuffixTrie
{
private:
SuffixTrieNode root;
public:
SuffixTrie(string txt)
{
for (int i = 0; i < txt.length(); i++)
root.insertSuffix(txt.substr(i), i);
}
void search(string pat);
};
void SuffixTrieNode::insertSuffix(string s, int index)
{
indexes->push_back(index);
if (s.length() > 0)
{
char cIndex = s.at(0);
if (children[cIndex] == NULL)
children[cIndex] = new SuffixTrieNode();
children[cIndex]->insertSuffix(s.substr(1), index+1);
}
}
list<int>* SuffixTrieNode::search(string s)
{
if (s.length() == 0)
return indexes;
if (children[s.at(0)] != NULL)
return (children[s.at(0)])->search(s.substr(1));
else return NULL;
}
void SuffixTrie::search(string pat)
{
list<int> *result = root.search(pat);
if (result == NULL)
cout << "Pattern not found" << endl;
else
{
list<int>::iterator i;
int patLen = pat.length();
for (i = result->begin(); i != result->end(); ++i)
cout << "Pattern found at position " << *i - patLen<< endl;
}
}
int main()
{
string txt = "geeksforgeeks.org";
SuffixTrie S(txt);
cout << "Search for 'ee'" << endl;
S.search("ee");
cout << "\nSearch for 'geek'" << endl;
S.search("geek");
cout << "\nSearch for 'quiz'" << endl;
S.search("quiz");
cout << "\nSearch for 'forgeeks'" << endl;
S.search("forgeeks");
return 0;
}
|
Java
import java.util.LinkedList;
import java.util.List;
class SuffixTrieNode {
final static int MAX_CHAR = 256;
SuffixTrieNode[] children = new SuffixTrieNode[MAX_CHAR];
List<Integer> indexes;
SuffixTrieNode()
{
indexes = new LinkedList<Integer>();
for (int i = 0; i < MAX_CHAR; i++)
children[i] = null;
}
void insertSuffix(String s, int index) {
indexes.add(index);
if (s.length() > 0) {
char cIndex = s.charAt(0);
if (children[cIndex] == null)
children[cIndex] = new SuffixTrieNode();
children[cIndex].insertSuffix(s.substring(1),
index + 1);
}
}
List<Integer> search(String s) {
if (s.length() == 0)
return indexes;
if (children[s.charAt(0)] != null)
return (children[s.charAt(0)]).search(s.substring(1));
else
return null;
}
}
class Suffix_tree{
SuffixTrieNode root = new SuffixTrieNode();
Suffix_tree(String txt) {
for (int i = 0; i < txt.length(); i++)
root.insertSuffix(txt.substring(i), i);
}
void search_tree(String pat) {
List<Integer> result = root.search(pat);
if (result == null)
System.out.println("Pattern not found");
else {
int patLen = pat.length();
for (Integer i : result)
System.out.println("Pattern found at position " +
(i - patLen));
}
}
public static void main(String args[]) {
String txt = "geeksforgeeks.org";
Suffix_tree S = new Suffix_tree(txt);
System.out.println("Search for 'ee'");
S.search_tree("ee");
System.out.println("\nSearch for 'geek'");
S.search_tree("geek");
System.out.println("\nSearch for 'quiz'");
S.search_tree("quiz");
System.out.println("\nSearch for 'forgeeks'");
S.search_tree("forgeeks");
}
}
|
C#
using System;
using System.Collections.Generic;
class SuffixTrieNode
{
static int MAX_CHAR = 256;
public SuffixTrieNode[] children = new SuffixTrieNode[MAX_CHAR];
public List<int> indexes;
public SuffixTrieNode()
{
indexes = new List<int>();
for (int i = 0; i < MAX_CHAR; i++)
children[i] = null;
}
public void insertSuffix(String s, int index)
{
indexes.Add(index);
if (s.Length > 0)
{
char cIndex = s[0];
if (children[cIndex] == null)
children[cIndex] = new SuffixTrieNode();
children[cIndex].insertSuffix(s.Substring(1),
index + 1);
}
}
public List<int> search(String s)
{
if (s.Length == 0)
return indexes;
if (children[s[0]] != null)
return (children[s[0]]).search(s.Substring(1));
else
return null;
}
}
public class Suffix_tree
{
SuffixTrieNode root = new SuffixTrieNode();
Suffix_tree(String txt)
{
for (int i = 0; i < txt.Length; i++)
root.insertSuffix(txt.Substring(i), i);
}
void search_tree(String pat)
{
List<int> result = root.search(pat);
if (result == null)
Console.WriteLine("Pattern not found");
else
{
int patLen = pat.Length;
foreach (int i in result)
Console.WriteLine("Pattern found at position " +
(i - patLen));
}
}
public static void Main(String []args)
{
String txt = "geeksforgeeks.org";
Suffix_tree S = new Suffix_tree(txt);
Console.WriteLine("Search for 'ee'");
S.search_tree("ee");
Console.WriteLine("\nSearch for 'geek'");
S.search_tree("geek");
Console.WriteLine("\nSearch for 'quiz'");
S.search_tree("quiz");
Console.WriteLine("\nSearch for 'forgeeks'");
S.search_tree("forgeeks");
}
}
|
Javascript
<script>
let MAX_CHAR = 256;
class SuffixTrieNode
{
constructor()
{
this.indexes = [];
this.children = new Array(MAX_CHAR);
for(let i = 0; i < MAX_CHAR; i++)
{
this.children[i] = 0;
}
}
insertSuffix(s,index)
{
this.indexes.push(index);
if (s.length > 0)
{
let cIndex = s[0];
if (this.children[cIndex] == null)
this.children[cIndex] = new SuffixTrieNode();
this.children[cIndex].insertSuffix(s.substring(1),
index + 1);
}
}
search(s)
{
if (s.length == 0)
return this.indexes;
if (this.children[s[0]] != null)
return(this.children[s[0]].search(
s.substring(1)));
else
return null;
}
}
let root = new SuffixTrieNode();
function Suffix_tree(txt)
{
for(let i = 0; i < txt.length; i++)
root.insertSuffix(txt.substring(i), i);
}
function search_tree(pat)
{
let result = root.search(pat);
if (result == null)
document.write("Pattern not found<br>");
else
{
let patLen = pat.length;
for(let i of result.values())
document.write("Pattern found at position " +
(i - patLen)+"<br>");
}
}
let txt = "geeksforgeeks.org";
Suffix_tree(txt);
document.write("Search for 'ee'<br>");
search_tree("ee");
document.write("<br>Search for 'geek'<br>");
search_tree("geek");
document.write("<br>Search for 'quiz'<br>");
search_tree("quiz");
document.write("<br>Search for 'forgeeks'<br>");
search_tree("forgeeks");
</script>
|
Python3
class SuffixTrieNode:
def __init__(self):
self.children = [None] * 256
self.indexes = []
def insert_suffix(self, suffix, index):
self.indexes.append(index)
if suffix:
c_index = ord(suffix[0])
if not self.children[c_index]:
self.children[c_index] = SuffixTrieNode()
self.children[c_index].insert_suffix(suffix[1:], index + 1)
def search(self, pat):
if not pat:
return self.indexes
c_index = ord(pat[0])
if self.children[c_index]:
return self.children[c_index].search(pat[1:])
return None
class SuffixTrie:
def __init__(self, txt):
self.root = SuffixTrieNode()
for i in range(len(txt)):
self.root.insert_suffix(txt[i:], i)
def search(self, pat):
result = self.root.search(pat)
if not result:
print("Pattern not found")
else:
pat_len = len(pat)
for i in result:
print(f"Pattern found at position {i - pat_len}")
if __name__ == "__main__":
txt = "geeksforgeeks.org"
st = SuffixTrie(txt)
pat = "ee"
print(f"Search for '{pat}'")
st.search(pat)
print()
pat = "geek"
print(f"Search for '{pat}'")
st.search(pat)
print()
pat = "quiz"
print(f"Search for '{pat}'")
st.search(pat)
print()
pat = "forgeeks"
print(f"Search for '{pat}'")
st.search(pat)
print()
|
Output:
Search for 'ee'
Pattern found at position 1
Pattern found at position 9
Search for 'geek'
Pattern found at position 0
Pattern found at position 8
Search for 'quiz'
Pattern not found
Search for 'forgeeks'
Pattern found at position 5
Time Complexity of the above search function is O(m+k) where m is length of the pattern and k is the number of occurrences of pattern in text.
Space Complexity: O(n * MAX_CHAR) where n is the length of the input text.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...