- Courses
- Tutorials
- Jobs
- Practice
- Contests
Parsing and Syntax directed translation
Question 1
What is the maximum number of reduce moves that can be taken by a bottom-up parser for a grammar with no epsilon- and unit-production (i.e., of type A -> є and A -> a) to parse a string with n tokens?
Question 2
Consider the following two sets of LR(1) items of an LR(1) grammar.
X -> c.X, c/d X -> .cX, c/d X -> .d, c/d X -> c.X, $ X -> .cX, $ X -> .d, $Which of the following statements related to merging of the two sets in the corresponding LALR parser is/are FALSE?
- Cannot be merged since look aheads are different.
- Can be merged but will result in S-R conflict.
- Can be merged but will result in R-R conflict.
- Cannot be merged since goto on c will lead to two different sets.
Question 3
For the grammar below, a partial LL(1) parsing table is also presented along with the grammar. Entries that need to be filled are indicated as E1, E2, and E3. [Tex]\\epsilon[/Tex] is the empty string, $ indicates end of input, and, | separates alternate right hand sides of productions.
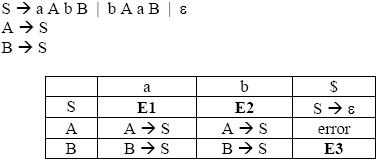



Question 4
Consider the date same as above question. The appropriate entries for E1, E2, and E3 are
[caption width="800"]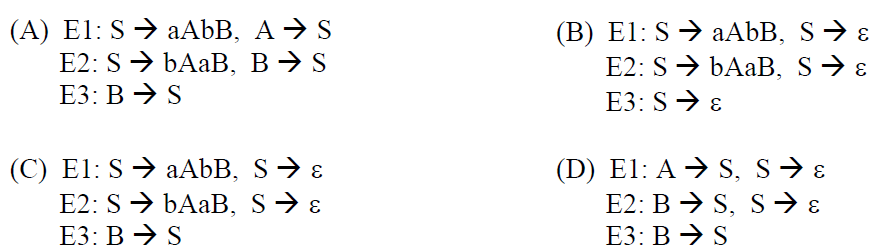 [/caption]
[/caption]Question 6
Match all items in Group 1 with correct options from those given in Group 2.
Group 1 Group 2 P. Regular expression 1. Syntax analysis Q. Pushdown automata 2. Code generation R. Dataflow analysis 3. Lexical analysis S. Register allocation 4. Code optimization
Question 7
Which of the following statements are TRUE?
I. There exist parsing algorithms for some programming languages
whose complexities are less than O(n3).
II. A programming language which allows recursion can be implemented
with static storage allocation.
III. No L-attributed definition can be evaluated in The framework
of bottom-up parsing.
IV. Code improving transformations can be performed at both source
language and intermediate code level.
Question 8
Which of the following describes a handle (as applicable to LR-parsing) appropriately?
Question 9
An LALR(1) parser for a grammar G can have shift-reduce (S-R) conflicts if and only if
There are 85 questions to complete.
Last Updated :
Take a part in the ongoing discussion