Parallelism in Query in DBMS
Last Updated :
13 Apr, 2022
Parallelism in a query allows us to parallel execution of multiple queries by decomposing them into the parts that work in parallel. This can be achieved by shared-nothing architecture. Parallelism is also used in fastening the process of a query execution as more and more resources like processors and disks are provided. We can achieve parallelism in a query by the following methods :
- I/O parallelism
- Intra-query parallelism
- Inter-query parallelism
- Intra-operation parallelism
- Inter-operation parallelism
1. I/O parallelism :
It is a form of parallelism in which the relations are partitioned on multiple disks a motive to reduce the retrieval time of relations from the disk. Within, the data inputted is partitioned and then processing is done in parallel with each partition. The results are merged after processing all the partitioned data. It is also known as data-partitioning. Hash partitioning has the advantage that it provides an even distribution of data across the disks and it is also best suited for those point queries that are based on the partitioning attribute. It is to be noted that partitioning is useful for the sequential scans of the entire table placed on ‘n‘ number of disks and the time taken to scan the relationship is approximately 1/n of the time required to scan the table on a single disk system. We have four types of partitioning in I/O parallelism:
- Hash partitioning –
As we already know, a Hash Function is a fast, mathematical function. Each row of the original relationship is hashed on partitioning attributes. For example, let’s assume that there are 4 disks disk1, disk2, disk3, and disk4 through which the data is to be partitioned. Now if the Function returns 3, then the row is placed on disk3.
- Range partitioning –
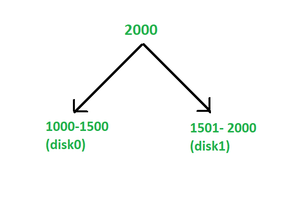
In range partitioning, it issues continuous attribute value ranges to each disk. For example, we have 3 disks numbered 0, 1, and 2 in range partitioning, and may assign relation with a value that is less than 5 to disk0, values between 5-40 to disk1, and values that are greater than 40 to disk2. It has some advantages, like it involves placing shuffles containing attribute values that fall within a certain range on the disk. See figure 1: Range partitioning given below:
- Round-robin partitioning –
In Round Robin partitioning, the relations are studied in any order. The ith tuple is sent to the disk number(i % n). So, disks take turns receiving new rows of data. This technique ensures the even distribution of tuples across disks and is ideally suitable for applications that wish to read the entire relation sequentially for each query.
- Schema partitioning –
In schema partitioning, different tables within a database are placed on different disks. See figure 2 below:

figure – 2
2. Intra-query parallelism :
Intra-query parallelism refers to the execution of a single query in a parallel process on different CPUs using a shared-nothing paralleling architecture technique. This uses two types of approaches:
- First approach –
In this approach, each CPU can execute the duplicate task against some data portion.
- Second approach –
In this approach, the task can be divided into different sectors with each CPU executing a distinct subtask.
3. Inter-query parallelism :
In Inter-query parallelism, there is an execution of multiple transactions by each CPU. It is called parallel transaction processing. DBMS uses transaction dispatching to carry inter query parallelism. We can also use some different methods, like efficient lock management. In this method, each query is run sequentially, which leads to slowing down the running of long queries. In such cases, DBMS must understand the locks held by different transactions running on different processes. Inter query parallelism on shared disk architecture performs best when transactions that execute in parallel do not accept the same data. Also, it is the easiest form of parallelism in DBMS, and there is an increased transaction throughput.
4. Intra-operation parallelism :
Intra-operation parallelism is a sort of parallelism in which we parallelize the execution of each individual operation of a task like sorting, joins, projections, and so on. The level of parallelism is very high in intra-operation parallelism. This type of parallelism is natural in database systems. Let’s take an SQL query example:
SELECT * FROM Vehicles ORDER BY Model_Number;
In the above query, the relational operation is sorting and since a relation can have a large number of records in it, the operation can be performed on different subsets of the relation in multiple processors, which reduces the time required to sort the data.
5. Inter-operation parallelism :
When different operations in a query expression are executed in parallel, then it is called inter-operation parallelism. They are of two types –
- Pipelined parallelism –
In pipeline parallelism, the output row of one operation is consumed by the second operation even before the first operation has produced the entire set of rows in its output. Also, it is possible to run these two operations simultaneously on different CPUs, so that one operation consumes tuples in parallel with another operation, reducing them. It is useful for the small number of CPUs and avoids writing of intermediate results to disk.
- Independent parallelism –
In this parallelism, the operations in query expressions that are not dependent on each other can be executed in parallel. This parallelism is very useful in the case of the lower degree of parallelism.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...