Object Detection vs Object Recognition vs Image Segmentation
Last Updated :
28 Jun, 2022
Object Recognition:
Object recognition is the technique of identifying the object present in images and videos. It is one of the most important applications of machine learning and deep learning. The goal of this field is to teach machines to understand (recognize) the content of an image just like humans do.
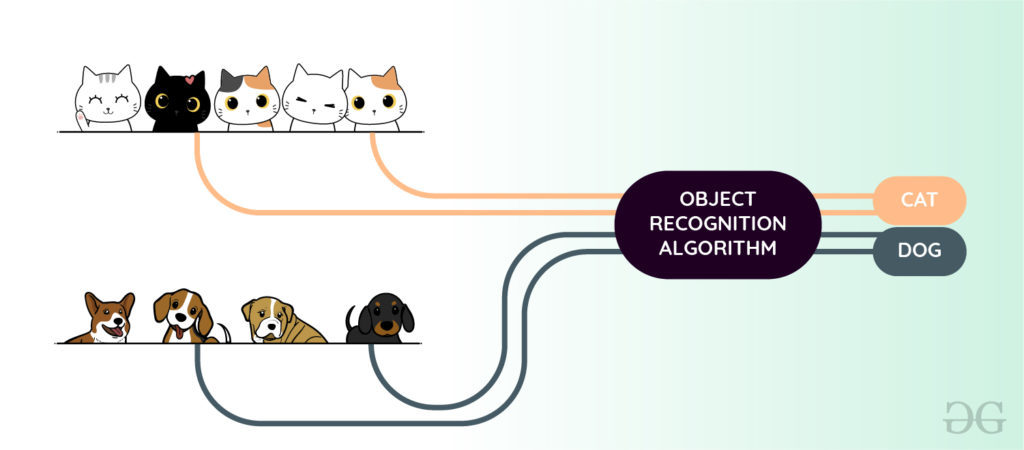
Object Recognition
Object Recognition Using Machine Learning
- HOG (Histogram of oriented Gradients) feature Extractor and SVM (Support Vector Machine) model: Before the era of deep learning, it was a state-of-the-art method for object detection. It takes histogram descriptors of both positive ( images that contain objects) and negative (images that does not contain objects) samples and trains our SVM model on that.
- Bag of features model: Just like bag of words considers document as an orderless collection of words, this approach also represents an image as an orderless collection of image features. Examples of this are SIFT, MSER, etc.
- Viola-Jones algorithm: This algorithm is widely used for face detection in the image or real-time. It performs Haar-like feature extraction from the image. This generates a large number of features. These features are then passed into a boosting classifier. This generates a cascade of the boosted classifier to perform image detection. An image needs to pass to each of the classifiers to generate a positive (face found) result. The advantage of Viola-Jones is that it has a detection time of 2 fps which can be used in a real-time face recognition system.
Object Recognition Using Deep Learning
Convolution Neural Network (CNN) is one of the most popular ways of doing object recognition. It is widely used and most state-of-the-art neural networks used this method for various object recognition related tasks such as image classification. This CNN network takes an image as input and outputs the probability of the different classes. If the object present in the image then it’s output probability is high else the output probability of the rest of classes is either negligible or low. The advantage of Deep learning is that we don’t need to do feature extraction from data as compared to machine learning. 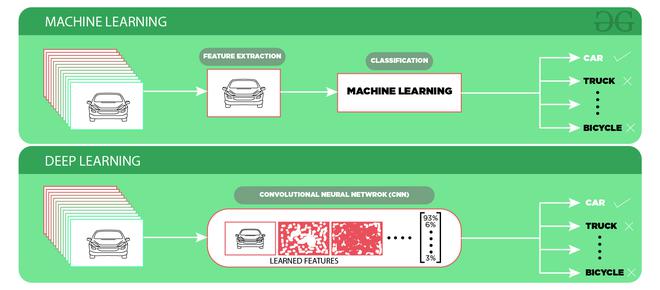
Challenges of Object Recognition:
- Since we take the output generated by last (fully connected) layer of the CNN model is a single class label. So, a simple CNN approach will not work if more than one class labels are present in the image.
- If we want to localize the presence of an object in the bounding box, we need to try a different approach that not only outputs the class label but also outputs the bounding box locations.
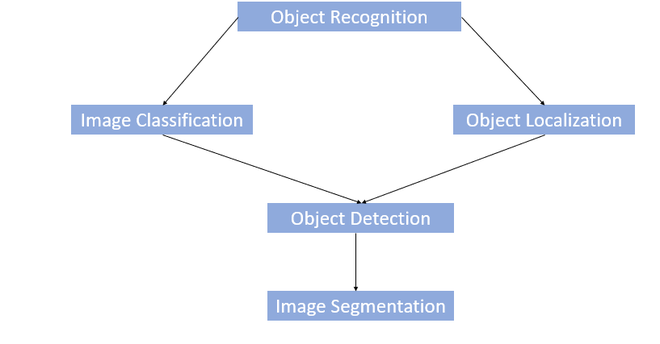
Overview of tasks related to Object Recognition
Image Classification :
In Image classification, it takes an image as an input and outputs the classification label of that image with some metric (probability, loss, accuracy, etc). For Example: An image of a cat can be classified as a class label “cat” or an image of Dog can be classified as a class label “dog” with some probability.

Image Classification
Object Localization: This algorithm locates the presence of an object in the image and represents it with a bounding box. It takes an image as input and outputs the location of the bounding box in the form of (position, height, and width).
Object Detection:
Object Detection algorithms act as a combination of image classification and object localization. It takes an image as input and produces one or more bounding boxes with the class label attached to each bounding box. These algorithms are capable enough to deal with multi-class classification and localization as well as to deal with the objects with multiple occurrences.
Challenges of Object Detection:
- In object detection, the bounding boxes are always rectangular. So, it does not help with determining the shape of objects if the object contains the curvature part.
- Object detection cannot accurately estimate some measurements such as the area of an object, perimeter of an object from image.
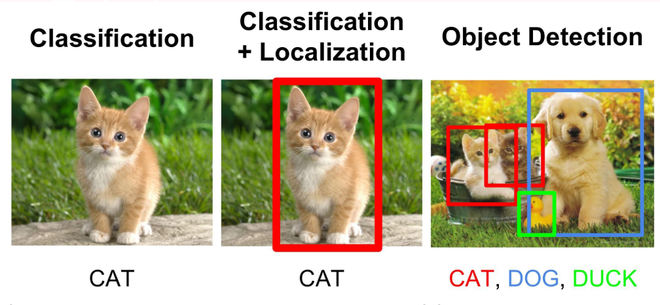
Difference between classification. Localization and Detection (Source: Link)
Image Segmentation:
Image segmentation is a further extension of object detection in which we mark the presence of an object through pixel-wise masks generated for each object in the image. This technique is more granular than bounding box generation because this can helps us in determining the shape of each object present in the image because instead of drawing bounding boxes , segmentation helps to figure out pixels that are making that object. This granularity helps us in various fields such as medical image processing, satellite imaging, etc. There are many image segmentation approaches proposed recently. One of the most popular is Mask R-CNN proposed by K He et al. in 2017.
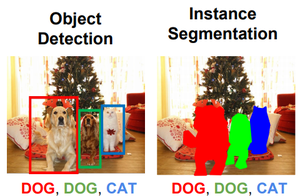
Object Detection vs Segmentation (Source: Link)
There are primarily two types of segmentation:
- Instance Segmentation: Multiple instances of same class are separate segments i.e. objects of same class are treated as different. Therefore, all the objects are coloured with different colour even if they belong to same class.
- Semantic Segmentation: All objects of same class form a single classification ,therefore , all objects of same class are coloured by same colour.
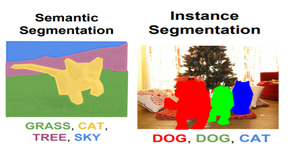
Semantic vs Instance Segmentation (Source: Link)
Applications:
The above-discussed object recognition techniques can be utilized in many fields such as:
- Driver-less Cars: Object Recognition is used for detecting road signs, other vehicles, etc.
- Medical Image Processing: Object Recognition and Image Processing techniques can help detect disease more accurately. Image segmentation helps to detect the shape of the defect present in the body . For Example, Google AI for breast cancer detection detects more accurately than doctors.
- Surveillance and Security: such as Face Recognition, Object Tracking, Activity Recognition, etc.
References:
- Ross Girshick’s RCNN paper
- Mathworks Object Recognition vs Object Detection
- CS231n Stanford Slides
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...