What are Chunks?
Chunks are made up of words and the kinds of words are defined using the part-of-speech tags. One can even define a pattern or words that can’t be a part of chuck and such words are known as chinks.
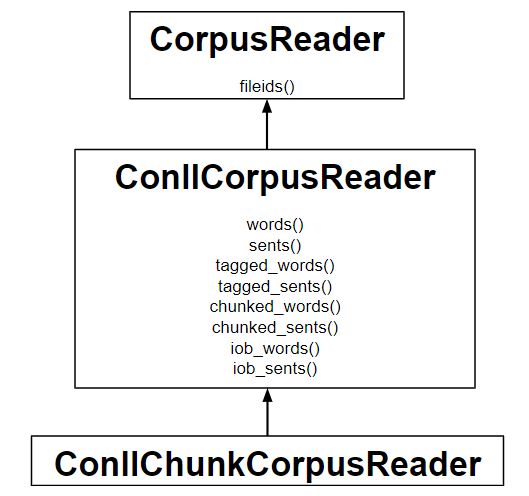
What are IOB tags?
It is a format for chunks. These tags are similar to part-of-speech tags but can denote the inside, outside, and beginning of a chunk. Not just noun phrases but multiple different chunk phrase types are allowed here.
Example: It is an excerpt from the conll2000 corpus. Each word is with a part-of-speech tag followed by an IOB tag on its own line:
Mr. NNP B-NP
Meador NNP I-NP
had VBD B-VP
been VBN I-VP
executive JJ B-NP
vice NN I-NP
president NN I-NP
of IN B-PP
Balcor NNP B-NP
What does it mean?
B-NP: the beginning of a noun phrase
I-NP: describes that the word is inside of the current noun phrase.
O: end of the sentence.
B-VP and I-VP: beginning and inside of a verb phrase.
Code #1: How it works – chunking words with IOB tags.
Python3
from nltk.corpus.reader import ConllChunkCorpusReader
reader = ConllChunkCorpusReader(
'.', r'.*\.iob', ('NP', 'VP', 'PP'))
reader.chunked_words()
reader.iob_words()
|
Output :
[Tree('NP', [('Mr.', 'NNP'), ('Meador', 'NNP')]), Tree('VP', [('had', 'VBD'),
('been', 'VBN')]), ...]
[('Mr.', 'NNP', 'B-NP'), ('Meador', 'NNP', 'I-NP'), ...]
Code #2: How it works – chunking sentence with IOB tags.
Python3
from nltk.corpus.reader import ConllChunkCorpusReader
reader = ConllChunkCorpusReader(
'.', r'.*\.iob', ('NP', 'VP', 'PP'))
reader.chunked_sents()
reader.iob_sents()
|
Output :
[Tree('S', [Tree('NP', [('Mr.', 'NNP'), ('Meador', 'NNP')]),
Tree('VP', [('had', 'VBD'), ('been', 'VBN')]),
Tree('NP', [('executive', 'JJ'), ('vice', 'NN'), ('president', 'NN')]),
Tree('PP', [('of', 'IN')]), Tree('NP', [('Balcor', 'NNP')]), ('.', '.')])]
[[('Mr.', 'NNP', 'B-NP'), ('Meador', 'NNP', 'I-NP'), ('had', 'VBD', 'B-VP'),
('been', 'VBN', 'I-VP'), ('executive', 'JJ', 'B-NP'), ('vice', 'NN', 'I-NP'),
('president', 'NN', 'I-NP'), ('of', 'IN', 'B-PP'), ('Balcor', 'NNP', 'B-NP'),
('.', '.', 'O')]]
Let’s understand the code above :
- For reading the corpus with IOB format, ConllChunkCorpusReader class is used.
- No separation of paragraphs and each sentence is separated by a blank line, therefore para_* methods are not available.
- Tuple or list specifying the types of chunks in the file like (‘NP’, ‘VP’, ‘PP’) serves as the third argument to ConllChunkCorpusReader.
- iob_words() and iob_sents() methods returns lists of three tuples of (word, pos, iob)
Code #3: Tree Leaves – i.e. the tagged tokens
Python3
from nltk.corpus.reader import ConllChunkCorpusReader
reader = ConllChunkCorpusReader(
'.', r'.*\.iob', ('NP', 'VP', 'PP'))
reader.chunked_words()[0].leaves()
reader.chunked_sents()[0].leaves()
reader.chunked_paras()[0][0].leaves()
|
Output :
[('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS')]
[('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS'),
('have', 'VBP'), ('trimmed', 'VBN'), ('about', 'IN'), ('300', 'CD'),
('jobs', 'NNS'), (', ', ', '), ('the', 'DT'), ('spokesman', 'NN'),
('said', 'VBD'), ('.', '.')]
[('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS'),
('have', 'VBP'), ('trimmed', 'VBN'), ('about', 'IN'), ('300', 'CD'),
('jobs', 'NNS'), (', ', ', '), ('the', 'DT'), ('spokesman', 'NN'),
('said', 'VBD'), ('.', '.')]
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...