Network File System (NFS)
Last Updated :
06 Feb, 2023
The advent of distributed computing was marked by the introduction of distributed file systems. Such systems involved multiple client machines and one or a few servers. The server stores data on its disks and the clients may request data through some protocol messages. Advantages of a distributed file system:
- Allows easy sharing of data among clients.
- Provides centralized administration.
- Provides security, i.e. one must only secure the servers to secure data.
Distributed File System Architecture:
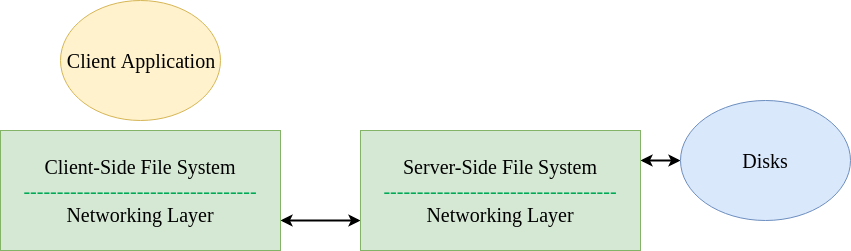
Even a simple client/server architecture involves more components than the physical file systems discussed previously in OS. The architecture consists of a client-side file system and a server-side file system. A client application issues a system call (e.g. read(), write(), open(), close() etc.) to access files on the client-side file system, which in turn retrieves files from the server. It is interesting to note that to a client application, the process seems no different than requesting data from a physical disk, since there is no special API required to do so. This phenomenon is known as transparency in terms of file access. It is the client-side file system that executes commands to service these system calls. For instance, assume that a client application issues the read() system call. The client-side file system then messages the server-side file system to read a block from the server’s disk and return the data back to the client. Finally, it buffers this data into the read() buffer and completes the system call. The server-side file system is also simply called the file server. Sun’s Network File System: The earliest successful distributed system could be attributed to Sun Microsystems, which developed the Network File System (NFS). NFSv2 was the standard protocol followed for many years, designed with the goal of simple and fast server crash recovery. This goal is of utmost importance in multi-client and single-server based network architectures because a single instant of server crash means that all clients are unserviced. The entire system goes down. Stateful protocols make things complicated when it comes to crashes. Consider a client A trying to access some data from the server. However, just after the first read, the server crashed. Now, when the server is up and running, client A issues the second read request. However, the server does not know which file the client is referring to, since all that information was temporary and lost during the crash. Stateless protocols come to our rescue. Such protocols are designed so as to not store any state information in the server. The server is unaware of what the clients are doing — what blocks they are caching, which files are opened by them and where their current file pointers are. The server simply delivers all the information that is required to service a client request. If a server crash happens, the client would simply have to retry the request. Because of their simplicity, NFS implements a stateless protocol. File Handles: NFS uses file handles to uniquely identify a file or a directory that the current operation is being performed upon. This consists of the following components:
- Volume Identifier – An NFS server may have multiple file systems or partitions. The volume identifier tells the server which file system is being referred to.
- Inode Number – This number identifies the file within the partition.
- Generation Number – This number is used while reusing an inode number.
File Attributes: “File attributes” is a term commonly used in NFS terminology. This is a collective term for the tracked metadata of a file, including file creation time, last modified, size, ownership permissions etc. This can be accessed by calling stat() on the file. NFSv2 Protocol: Some of the common protocol messages are listed below.
| Message |
Description |
| NFSPROC_GETATTR |
Given a file handle, returns file attributes. |
| NFSPROC_SETATTR |
Sets/updates file attributes. |
| NFSPROC_LOOKUP |
Given file handle and name of the file to look up, returns file handle. |
| NFSPROC_READ |
Given file handle, offset, count data and attributes, reads the data. |
| NFSPROC_WRITE |
Given file handle, offset, count data and attributes, writes data into the file. |
| NFSPROC_CREATE |
Given the directory handle, name of file and attributes, creates a file. |
| NFSPROC_REMOVE |
Given the directory handle and name of file, deletes the file. |
| NFSPROC_MKDIR |
Given directory handle, name of directory and attributes, creates a new directory. |
The LOOKUP protocol message is used to obtain the file handle for further accessing data. The NFS mount protocol helps obtain the directory handle for the root (/) directory in the file system. If a client application opens a file /abc.txt, the client-side file system will send a LOOKUP request to the server, through the root (/) file handle looking for a file named abc.txt. If the lookup is successful, the file attributes are returned. Client-Side Caching: To improve performance of NFS, distributed file systems cache the data as well as the metadata read from the server onto the clients. This is known as client-side caching. This reduces the time taken for subsequent client accesses. The cache is also used as a temporary buffer for writing. This helps improve efficiency even more since all writes are written onto the server at once.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...