As we know that while dealing with a high dimensional dataset then we must apply some dimensionality reduction techniques to the data at hand so, that we can explore the data and utilize it for modeling in an efficient manner. In this article, we will learn about one such dimensionality reduction technique that is used to map high dimensional data to a comparatively lower dimension without much data loss.
What is Linear Discriminant Analysis?
Linear Discriminant Analysis (LDA), also known as Normal Discriminant Analysis or Discriminant Function Analysis, is a dimensionality reduction technique primarily utilized in supervised classification problems. It facilitates the modeling of distinctions between groups, effectively separating two or more classes. LDA operates by projecting features from a higher-dimensional space into a lower-dimensional one. In machine learning, LDA serves as a supervised learning algorithm specifically designed for classification tasks, aiming to identify a linear combination of features that optimally segregates classes within a dataset.
For example, we have two classes and we need to separate them efficiently. Classes can have multiple features. Using only a single feature to classify them may result in some overlapping as shown in the below figure. So, we will keep on increasing the number of features for proper classification.
Assumptions of LDA
LDA assumes that the data has a Gaussian distribution and that the covariance matrices of the different classes are equal. It also assumes that the data is linearly separable, meaning that a linear decision boundary can accurately classify the different classes.
Suppose we have two sets of data points belonging to two different classes that we want to classify. As shown in the given 2D graph, when the data points are plotted on the 2D plane, there’s no straight line that can separate the two classes of data points completely. Hence, in this case, LDA (Linear Discriminant Analysis) is used which reduces the 2D graph into a 1D graph in order to maximize the separability between the two classes.
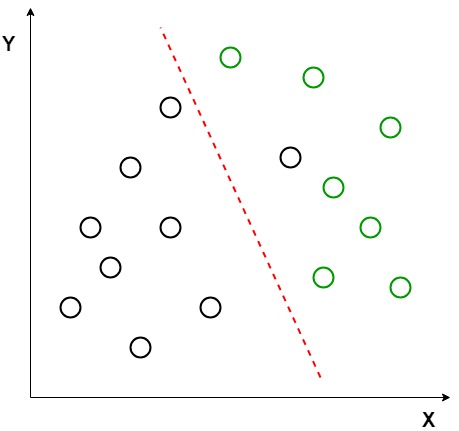
Linearly Separable Dataset
Here, Linear Discriminant Analysis uses both axes (X and Y) to create a new axis and projects data onto a new axis in a way to maximize the separation of the two categories and hence, reduces the 2D graph into a 1D graph.
Two criteria are used by LDA to create a new axis:
- Maximize the distance between the means of the two classes.
- Minimize the variation within each class.
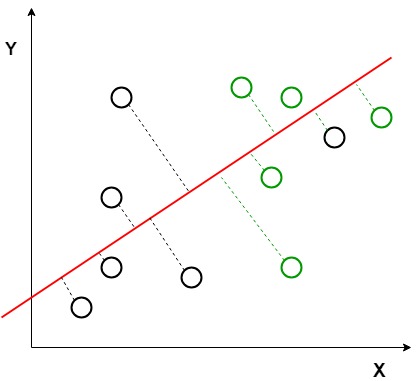
The perpendicular distance between the line and points
In the above graph, it can be seen that a new axis (in red) is generated and plotted in the 2D graph such that it maximizes the distance between the means of the two classes and minimizes the variation within each class. In simple terms, this newly generated axis increases the separation between the data points of the two classes. After generating this new axis using the above-mentioned criteria, all the data points of the classes are plotted on this new axis and are shown in the figure given below.
But Linear Discriminant Analysis fails when the mean of the distributions are shared, as it becomes impossible for LDA to find a new axis that makes both classes linearly separable. In such cases, we use non-linear discriminant analysis.
How does LDA work?
LDA works by projecting the data onto a lower-dimensional space that maximizes the separation between the classes. It does this by finding a set of linear discriminants that maximize the ratio of between-class variance to within-class variance. In other words, it finds the directions in the feature space that best separates the different classes of data.
Mathematical Intuition Behind LDA
Let’s suppose we have two classes and a d- dimensional samples such as x1, x2 … xn, where:
- n1 samples coming from the class (c1) and n2 coming from the class (c2).
If xi is the data point, then its projection on the line represented by unit vector v can be written as vTxi
Let’s consider u1 and u2 to be the means of samples class c1 and c2 respectively before projection and u1hat denote the mean of the samples of class after projection and it can be calculated by:
[Tex]\widetilde{\mu_1} = \frac{1}{n_1}\sum_{x_i \in c_1}^{n_1} v^{T}x_i = v^{T} \mu_1 [/Tex]
Similarly,
[Tex]\widetilde{\mu_2} = v^{T} \mu_2[/Tex]
Now, In LDA we need to normalize |\widetilde{\mu_1} -\widetilde{\mu_2} |. Let y_i = v^{T}x_i be the projected samples, then scatter for the samples of c1 is:
[Tex]\widetilde{s_1^{2}} = \sum_{y_i \in c_1} (y_i – \mu_1)^2[/Tex]
Similarly:
[Tex]\widetilde{s_2^{2}} = \sum_{y_i \in c_1} (y_i – \mu_2)^2[/Tex]
Now, we need to protect our data on the line having direction v which maximizes,
[Tex]J(v) = \frac{\widetilde{\mu_1} – \widetilde{\mu_2}}{\widetilde{s_1^{2}} + \widetilde{s_2^{2}}}[/Tex]
For maximizing the above equation we need to find a projection vector that maximizes the difference of means of reducing the scatters of both classes. Now, scatter matrix of s1 and s2 of classes c1 and c2 are:
[Tex]s_1 = \sum_{x_i \in c_1} (x_i – \mu_1)(x_i – \mu_1)^{T} [/Tex]
and s2
[Tex]s_2 = \sum_{x_i \in c_2} (x_i – \mu_2)(x_i – \mu_2)^{T} [/Tex]
After simplifying the above equation, we get scatter within the classes(sw) and scatter b/w the classes(sb):
[Tex]s_w = s_1 + s_2 \\ \\ s_b = (\mu_1 – \mu_2) (\mu_1 – \mu_2 )^{T}[/Tex]
Now, we try to simplify the numerator part of J(v),
[Tex]J(v) = \frac{|\widetilde{\mu_1} – \widetilde{\mu_2}|}{\widetilde{s_1^{2}} + \widetilde{s_2^{2}}} = \frac{v^{T}s_{b}v}{v^{T}s_{w}v}[/Tex]
Now, To maximize the above equation we need to calculate differentiation with respect to v,
[Tex]\frac{d J(v)}{dv} = s_b v – \frac{v^{t}s_{b} v (s_w v)}{v^{T} s_w v} \\ \\ = s_b v – \lambda s_w v =0 \\ \\ s_b v = \lambda s_w v \\ \\ s_w^{-1} s_b v = \lambda v \\ \\ M v = \lambda v \\ \\ where, \\ \\ \lambda = \frac{v^{T}s_{b} v}{v^{T} s_w v} and \\ \\ M = s_w^{-1} s_b[/Tex]
Here, for the maximum value of J(v), we will use the value corresponding to the highest eigenvalue. This will provide us with the best solution for LDA.
Extensions to LDA
- Quadratic Discriminant Analysis (QDA): Each class uses its own estimate of variance (or covariance when there are multiple input variables).
- Flexible Discriminant Analysis (FDA): Where non-linear combinations of inputs are used such as splines.
- Regularized Discriminant Analysis (RDA): Introduces regularization into the estimate of the variance (actually covariance), moderating the influence of different variables on LDA.
Python Code Implementation of LDA
In this implementation, we will perform linear discriminant analysis using the Scikit-learn library on the Iris dataset.
Python3
# necessary import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
# load the iris dataset
iris = load_iris()
dataset = pd.DataFrame(columns=iris.feature_names,
data=iris.data)
dataset['target'] = iris.target
# divide the dataset into class and target variable
X = dataset.iloc[:, 0:4].values
y = dataset.iloc[:, 4].values
# Preprocess the dataset and divide into train and test
sc = StandardScaler()
X = sc.fit_transform(X)
le = LabelEncoder()
y = le.fit_transform(y)
X_train, X_test,\
y_train, y_test = train_test_split(X, y,
test_size=0.2)
# apply Linear Discriminant Analysis
lda = LinearDiscriminantAnalysis(n_components=2)
X_train = lda.fit_transform(X_train, y_train)
X_test = lda.transform(X_test)
# plot the scatterplot
plt.scatter(
X_train[:, 0], X_train[:, 1],
c=y_train,
cmap='rainbow',
alpha=0.7, edgecolors='b'
)
# classify using random forest classifier
classifier = RandomForestClassifier(max_depth=2,
random_state=0)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
# print the accuracy and confusion matrix
print('Accuracy : ' + str(accuracy_score(y_test, y_pred)))
conf_m = confusion_matrix(y_test, y_pred)
print(conf_m)
Output:
Accuracy : 0.9333333333333333
[[10 0 0]
[ 2 10 0]
[ 0 0 8]]

Scatter plot of the iris data mapped into 2D
Advanatages & Disadvantages of using LDA
Advanatages of using LDA
- It is a simple and computationally efficient algorithm.
- It can work well even when the number of features is much larger than the number of training samples.
- It can handle multicollinearity (correlation between features) in the data.
Disadvantages of LDA
- It assumes that the data has a Gaussian distribution, which may not always be the case.
- It assumes that the covariance matrices of the different classes are equal, which may not be true in some datasets.
- It assumes that the data is linearly separable, which may not be the case for some datasets.
- It may not perform well in high-dimensional feature spaces.
Applications of LDA
- Face Recognition: In the field of Computer Vision, face recognition is a very popular application in which each face is represented by a very large number of pixel values. Linear discriminant analysis (LDA) is used here to reduce the number of features to a more manageable number before the process of classification. Each of the new dimensions generated is a linear combination of pixel values, which form a template. The linear combinations obtained using Fisher’s linear discriminant are called Fisher’s faces.
- Medical: In this field, Linear discriminant analysis (LDA) is used to classify the patient’s disease state as mild, moderate, or severe based on the patient’s various parameters and the medical treatment he is going through. This helps the doctors to intensify or reduce the pace of their treatment.
- Customer Identification: Suppose we want to identify the type of customers who are most likely to buy a particular product in a shopping mall. By doing a simple question and answers survey, we can gather all the features of the customers. Here, a Linear discriminant analysis will help us to identify and select the features which can describe the characteristics of the group of customers that are most likely to buy that particular product in the shopping mall.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...