Linear Algebra principles are crucial for understanding the concept behind Machine Learning, as well as Deep Learning, even many ideas struggle to create a precise mathematical model, linear algebra continues to be an important tool for researching them.
This article will delve into Linear Algebra relevant for Machine Learning applications.
What is Linear Algebra?
It is a branch of mathematics that allows to define and perform operations on higher-dimensional coordinates and plane interactions in a concise way. Linear Algebra is an algebra extension to an undefined number of dimensions. Linear Algebra concerns the focus on linear equation systems. It is a continuous type of mathematics and is applicable in science and engineering, as it helps one to model and efficiently simulate natural phenomena. Before progressing to Linear Algebra concepts, we must understand the below properties:
- Associative Property: It is a property in Mathematics which states that if a, b and c are mathematical objects than a + (b + c) = (a + b) + c in which + is a binary operation.
- Commutative Property: It is a property in Mathematics which states that if a and b are mathematical objects then a + b = b + a in which + is a binary operation.
- Distributive Property: It is a property in Mathematics which states that if a, b and c are mathematical objects then a * (b + c)= (a * b) + (a * c) in which * and + are binary operators.
Linear Algebra for Machine learning
In the context of Machine Learning, linear algebra is employed to model and analyze relationships within data. It enables the representation of data points as vectors and allows for efficient computation of operations on these vectors. Linear transformations, matrices, and vector spaces play a significant role in defining and solving problems in ML.
The utilization of linear algebra in ML extends to solving systems of linear equations, optimizing models, and comprehending transformations inherent in algorithms like Principal Component Analysis (PCA). The integration of linear algebra in ML provides a powerful and versatile mathematical toolbox, to model, analyze, and optimize complex relationships within data, thereby advancing the capabilities of machine learning algorithms.
Importance of Linear Algebra in Machine Learning
Linear algebra is fundamental to machine learning due to its role in representing and solving systems of equations, defining transformations, and optimizing algorithms. It provides a mathematical framework for understanding and working with high-dimensional data, making it a cornerstone for various machine learning models and techniques.
Different ways to represent the Data in Linear Algebra
Linear algebra allows the representation of data using Scaler & vectors, enabling efficient storage and manipulation of large datasets.
Linear Algebra concepts used in Machine Learning for Representation of Data:
Scalar and Vector
- Scalar:
It is a physical quantity described using a single element, It has only magnitude and not direction. Basically, a scalar is just a single number.
Example: 17 and 256 - Vector:
It is a geometric object having both magnitude and direction, it is an ordered number array, and are always in a row or column. A Vector has just one index, which can refer to a particular value within the Vector.
[Tex]V= [e1,e2,e3,e4]
[/Tex]
Here V is a vector in which e1, e2, e3 and e4 are its elements, and V[2] is e3.
Vector Operations
1. Scalar-Vector Multiplication
p = [e1, e2, e3]
The product of a scalar with a vector gives the below result. When the scalar 2 is multiplied by a vector p then all the elements of the vector p is multiplied by that scalar. This operation satisfies commutative property.
p * 2 = [2 * e1, 2 * e2, 2 * e3]
Matrix
It is an ordered 2D array of numbers, symbols or expressions arranged in rows and columns. It has two indices, the first index points to the row, and the second index points to the column. A Matrix can have multiple numbers of rows and columns.
[Tex]M= \begin{bmatrix}
e1 & e2 \\
e3 & e4
\end{bmatrix}
[/Tex]
Above M is a 2D matrix having e1, e2, e3 and e4 as elements, and [Tex]M[1][0]
[/Tex]is e3.
A matrix having its left diagonal elements as 1 and other elements 0 is an Identity matrix.
Example:
[Tex]\begin{pmatrix}1 & 0 \\0 & 1\end{pmatrix}[/Tex] is 2D Identity Matrix.[Tex]\begin{pmatrix}1 & 0 & 0 \\0 & 1 & 0 \\0 & 0 & 1\end{pmatrix}[/Tex] is 3D Identity Matrix.
Tensor
It is an algebraic object representing a linear mapping of algebraic objects from one set to another. It is actually a 3D array of numbers with a variable number of axes, arranged on a regular grid. A tensor has three indices, first index points to the row, the second index points to the column and the third index points to the axis. 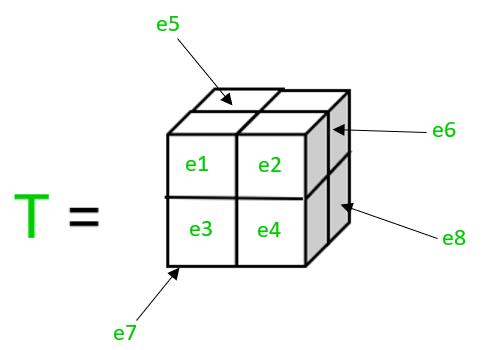 Here the tensor T has 8 elements [Tex]T = [e1, e2, e3, e4, e5, e6, e7, e8]
[/Tex], three-dimensional tensor with dimensions 2 x 2 x 2 such that [Tex] T[0][3][1] = e8[/Tex].
Here the tensor T has 8 elements [Tex]T = [e1, e2, e3, e4, e5, e6, e7, e8]
[/Tex], three-dimensional tensor with dimensions 2 x 2 x 2 such that [Tex] T[0][3][1] = e8[/Tex].
Tensors play a significant role in machine learning, particularly in deep learning, due to their ability to represent and manage multi-dimensional data.
Linear Algebra Operations
Machine learning models often involve transformations of data. Linear algebra provides a concise way to represent and analyze these transformations using matrices and linear operators.
Matrix Operations
1. Scalar-Matrix Multiplication
When the scalar a is multiplied by a matrix p then all the elements of the matrix p is multiplied by that scalar. Scalar-Matrix multiplication is associative, distributive and commutative.
p = [Tex][e1, e2, e3, e4][/Tex]a is a scalar.[Tex]p * a = (a * e1) (a * e2) (a * e3) (a * e4)[/Tex]
2. Matrix-Matrix Addition
In-order to add matrices the rows and columns of the matrices should be equal.Each element of the first matrix is added with the respective element of the another matrix both having same row and column value. Matrix-Matrix addition is associative, distributive and commutative. The addition of matrix m1 and m2 gives the below result.
[Tex]m1 + m2 = (a + p) (b + q)(c + r) (d + s)[/Tex]
3. Matrix-Matrix Subtraction
Each element of the first matrix is subtracted with the respective element of the another matrix both having same row and column value. Matrix-Matrix addition is associative, distributive and commutative. In-order to subtract matrices, the rows and columns of the matrices should be equal. The subtraction between matrix m1 and m2 gives the below result-
[Tex]m1 - m2 = (a - p) (b - q)(c - r) (d - s)[/Tex]
4. Matrix-Matrix Multiplication
- To multiply two matrices, the number of columns of the first matrix should be equal to the number of rows in the second matrix.Matrix-Matrix multiplication is associative and distributive but not commutative.The product of matrix m1 and m2 is given below
[Tex]m1 * m2 = ((a * p) + (b * r)) ((a * q) + (b * s)) ((c * p) + (d * r)) ((c * q) + (d * s))[/Tex]
Vector-Matrix Operations (Vector-Matrix Multiplication)
The number of rows of a matrix should be equal to the number of elements of the vector then only they can be multiplied. Vector-Matrix multiplication is associative and distributive but not commutative.
Multiplying a matrix p with a vector q gives the below product-
[Tex]p = [e1, e2, e3,e4 ,e5, e6][/Tex][Tex]q = a b[/Tex]
[Tex]p * q = [(e1 * a) + (e2 * b)][(e3 * a) + (e4 * b)][(e5 * a) + (e6 * b)][/Tex]
Transpose
The transpose of a matrix generates a new matrix in which the rows become columns and columns become rows of the original matrix. Transposition is vital for tasks like computing correlations and solving linear equations.
Transpose of an m*n matrix will give a n*m matrix.
[Tex]m=\begin{pmatrix}a & b \\c & d\end{pmatrix}[/Tex][Tex]Transpose(m) = \begin{pmatrix}a & c \\b & d\end{pmatrix} [/Tex]
Inverse
The inverse of a matrix is the matrix when multiplied with the original matrix gives the Identity matrix as the product. If m is a matrix and n is the inverse matrix of m, then m*n = I, in which I represent Identity matrix.
Eigenvalues and Eigenvectors
Understanding eigenvectors and eigenvalues provides insights into the behavior of linear transformations and is foundational in various fields, especially in the analysis of square matrices.
- In linear algebra, eigenvectors and eigenvalues are crucial for diagonalizing matrices. Diagonalization simplifies matrix operations, making computations more efficient.
- They are used in various applications, such as principal component analysis (PCA) in data analysis, solving systems of linear differential equations.
- They capture the intrinsic properties of a transformation or dataset.
Eigenvectors
Eigenvectors are special vectors that remain in the same direction after a linear transformation. When a matrix A is multiplied by its corresponding eigenvector:
[Tex]( \mathbf{v})[/Tex], the result is a scaled version of the original vector, i.e.,
[Tex]A\mathbf{v}=\lambda\mathbf{v}[/Tex],
where,
- \( [Tex]\lambda[/Tex] is the eigenvalue.
Eigenvectors are essentially the “directions” that remain unchanged, only scaled, when a transformation is applied.
Eigenvalues
Eigenvalues [Tex]\lambda[/Tex] are the scaling factors by which the eigenvectors are stretched or compressed during a linear transformation. They represent how much the eigenvector is “stretched” or “shrunk” by the linear transformation. Larger eigenvalues indicate a greater stretching, and smaller eigenvalues indicate compression.
Matrix Factorization
Matrix deposition techniques like SVD is one of the most suggested areas of linear algebra.
Singular Value Decomposition (SVD) is a powerful technique for decomposing a matrix into three constituent matrices: U, S, and VT. These matrices can be used to represent the matrix in a more compact and informative way.
SVD has a wide range of applications in machine learning, including:
- Data compression, noise reduction by discarding the smaller singular values and their corresponding singular vectors to reduce the storage requirements for data without significantly affecting its quality.
- Dimensionality reduction by keeping only the most important singular values and their corresponding singular vectors useful for tasks such as data visualization and feature extraction.
Linear Algebra in Machine Learning
Datasets in machine learning serve as the foundation for model training and evaluation. These datasets are essentially matrices, where each row represents a unique observation or data point, and each column represents a specific feature or variable. The tabular structure of datasets aligns with the principles of linear algebra, where matrices are fundamental entities.
Linear algebra provides the tools to manipulate and transform these datasets efficiently. Operations like matrix multiplication, addition, and decomposition are crucial for tasks such as feature engineering, data preprocessing, and computing various statistical measures. The representation of datasets as matrices allows for seamless integration of linear algebra techniques into the machine learning workflow.
- One-hot Encoding
In machine learning, dealing with categorical variables often involves converting them into a numerical format, and one-hot encoding is a prevalent technique for this purpose. It transforms categorical variables into binary vectors, where each category is represented by a column, and the presence or absence of that category is indicated by binary values.
The resulting one-hot encoded representation can be viewed as a sparse matrix, where most elements are zero, and linear algebra’s vector representation becomes evident. This compact encoding simplifies the handling of categorical data in machine learning algorithms, facilitating efficient computations and reducing the risk of bias associated with numerical encodings. - Linear Regression
Linear regression is a fundamental machine learning algorithm, and its implementation underscores the importance of linear algebra in the field. Linear algebra provides the mathematical foundation for understanding and solving the equations involved in linear regression. The use of matrices and vectors simplifies the formulation and computation, making the implementation more efficient and scalable. Understanding linear algebra is essential for grasping the underlying principles of linear regression and other machine learning algorithms. - Regularization
Regularization methods act as a form of constraint on the model’s complexity, encouraging simpler models with smaller coefficients. The elegant integration of linear algebra concepts into regularization techniques highlights the synergy between mathematical principles and practical machine learning challenges.
The regularization term in both L1 and L2 regularization is essentially a measure of the magnitude or length of the coefficient vector, a concept directly borrowed from linear algebra. In the case of L2 regularization, the penalty term is proportional to the Euclidean norm (L2 norm) of the coefficient vector, emphasizing the role of linear algebra’s vector norms in regularization. - Principal Component Analysis (PCA)
Principal Component Analysis (PCA) stands out as a powerful dimensionality reduction technique widely used in machine learning and data analysis. Its primary objective is to transform a high-dimensional dataset into a lower-dimensional representation while retaining as much variability as possible.
At its core, PCA involves the computation of eigenvectors and eigenvalues of the dataset’s covariance matrix—a task that aligns with linear algebra principles. The covariance matrix captures the relationships between different features, and its eigenvectors represent the principal components, or the directions of maximum variance. - Images and Photographs
Images and photographs, vital components of computer vision applications, are inherently structured as matrices of pixel values. Each pixel’s position corresponds to a specific element in the matrix, and its intensity is encoded as the value of that element. Linear algebra operations play a central role in image processing tasks, such as scaling, rotating, and filtering.
Transformations applied to images can be represented as matrix operations, making linear algebra an essential tool in image manipulation. For instance, a rotation transformation can be expressed as a matrix multiplication, showcasing the versatility of linear algebra in handling image data. - Deep Learning
Deep learning, characterized by artificial neural networks (ANNs) with multiple layers, relies extensively on linear algebra structures for both model representation and training. ANNs process information through interconnected nodes organized in layers, where each connection is associated with a weight.
The fundamental operations within a neural network—matrix multiplications and element-wise activations—are inherently linear algebraic. The input layer, hidden layers, and output layer collectively involve manipulating vectors, matrices, and tensors.
Conclusion
Linear algebra is the cornerstone of mathematical concepts in machine learning. A solid grasp of vectors, matrices, and operations like matrix multiplication is essential for understanding algorithms, developing models, and navigating the intricacies of data transformations. Aspiring machine learning practitioners benefit immensely from a strong foundation in linear algebra, enhancing their ability to innovate and contribute to this dynamic field.
Frequently Asked Questions(FAQs)
Q. Is linear algebra used in machine learning?
Yes, extensively. Linear algebra is fundamental in machine learning for tasks like representing data, defining models, solving equations, and optimizing algorithms.
Q. Can you learn machine learning without linear algebra?
While possible, learning machine learning without linear algebra limits understanding key concepts, making it challenging to grasp the underlying mechanisms.
Q. Is linear algebra useful for programming?
Yes, linear algebra is beneficial for programming, especially in areas like graphics, simulations, and machine learning, where it enhances efficiency and algorithm implementation.
Q. What topics of linear algebra are needed for machine learning?
Key linear algebra topics for machine learning include vectors, matrices, matrix operations, eigenvalues, eigenvectors, and matrix factorization methods like SVD.
Q. Is linear algebra used in algorithms?
linear algebra plays a crucial role in algorithm design, particularly in optimization algorithms, dimensionality reduction methods, and the development of various machine learning models and techniques.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...