ML | K-Medoids clustering with solved example
Last Updated :
11 Jan, 2023
K-Medoids (also called Partitioning Around Medoid) algorithm was proposed in 1987 by Kaufman and Rousseeuw. A medoid can be defined as a point in the cluster, whose dissimilarities with all the other points in the cluster are minimum. The dissimilarity of the medoid(Ci) and object(Pi) is calculated by using E = |Pi – Ci|
The cost in K-Medoids algorithm is given as

Algorithm:
- Initialize: select k random points out of the n data points as the medoids.
- Associate each data point to the closest medoid by using any common distance metric methods.
- While the cost decreases: For each medoid m, for each data o point which is not a medoid:
- Swap m and o, associate each data point to the closest medoid, and recompute the cost.
- If the total cost is more than that in the previous step, undo the swap.
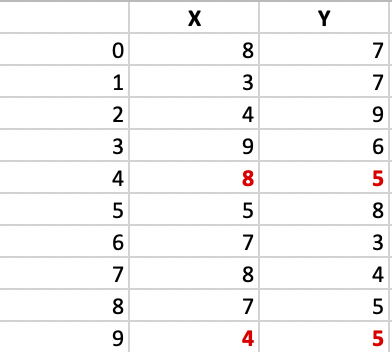
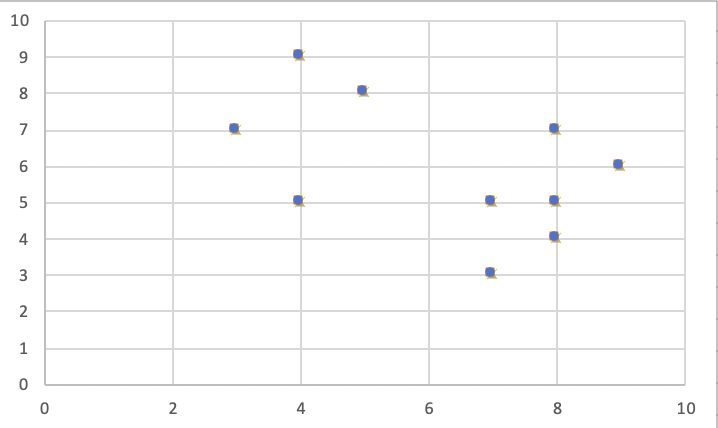
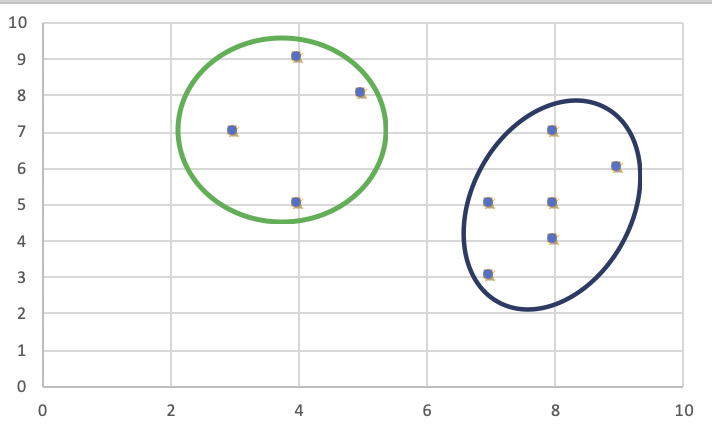
Let’s consider the following example: If a graph is drawn using the above data points, we obtain the following:
Step 1: Let the randomly selected 2 medoids, so select k = 2, and let C1 -(4, 5) and C2 -(8, 5) are the two medoids.
Step 2: Calculating cost. The dissimilarity of each non-medoid point with the medoids is calculated and tabulated:
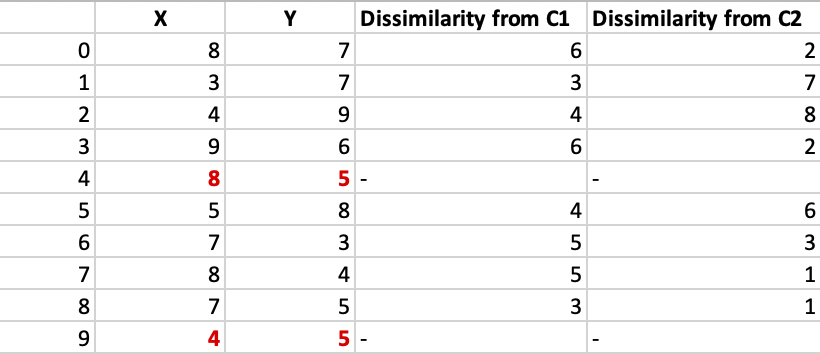
Here we have used Manhattan distance formula to calculate the distance matrices between medoid and non-medoid points. That formula tell that Distance = |X1-X2| + |Y1-Y2|.
Each point is assigned to the cluster of that medoid whose dissimilarity is less. Points 1, 2, and 5 go to cluster C1 and 0, 3, 6, 7, 8 go to cluster C2. The Cost = (3 + 4 + 4) + (3 + 1 + 1 + 2 + 2) = 20
Step 3: randomly select one non-medoid point and recalculate the cost. Let the randomly selected point be (8, 4). The dissimilarity of each non-medoid point with the medoids – C1 (4, 5) and C2 (8, 4) is calculated and tabulated.
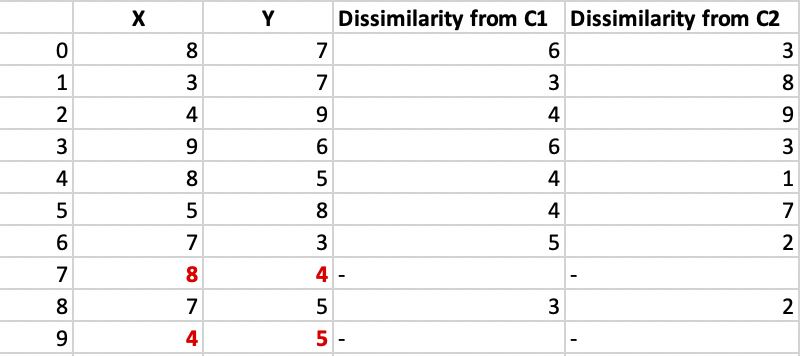
Each point is assigned to that cluster whose dissimilarity is less. So, points 1, 2, and 5 go to cluster C1 and 0, 3, 6, 7, 8 go to cluster C2. The New cost = (3 + 4 + 4) + (2 + 2 + 1 + 3 + 3) = 22 Swap Cost = New Cost – Previous Cost = 22 – 20 and 2 >0 As the swap cost is not less than zero, we undo the swap. Hence (4, 5) and (8, 5) are the final medoids. The clustering would be in the following way The time complexity is  .
.
Advantages:
- It is simple to understand and easy to implement.
- K-Medoid Algorithm is fast and converges in a fixed number of steps.
- PAM is less sensitive to outliers than other partitioning algorithms.
Disadvantages:
- The main disadvantage of K-Medoid algorithms is that it is not suitable for clustering non-spherical (arbitrarily shaped) groups of objects. This is because it relies on minimizing the distances between the non-medoid objects and the medoid (the cluster center) – briefly, it uses compactness as clustering criteria instead of connectivity.
- It may obtain different results for different runs on the same dataset because the first k medoids are chosen randomly.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...