Gradient Boosting in ML
Last Updated :
31 Mar, 2023
Gradient Boosting is a popular boosting algorithm in machine learning used for classification and regression tasks. Boosting is one kind of ensemble Learning method which trains the model sequentially and each new model tries to correct the previous model. It combines several weak learners into strong learners. There is two most popular boosting algorithm i.e
- AdaBoost
- Gradient Boosting
Gradient Boosting
Gradient Boosting is a powerful boosting algorithm that combines several weak learners into strong learners, in which each new model is trained to minimize the loss function such as mean squared error or cross-entropy of the previous model using gradient descent. In each iteration, the algorithm computes the gradient of the loss function with respect to the predictions of the current ensemble and then trains a new weak model to minimize this gradient. The predictions of the new model are then added to the ensemble, and the process is repeated until a stopping criterion is met.
In contrast to AdaBoost, the weights of the training instances are not tweaked, instead, each predictor is trained using the residual errors of the predecessor as labels. There is a technique called the Gradient Boosted Trees whose base learner is CART (Classification and Regression Trees). The below diagram explains how gradient-boosted trees are trained for regression problems.
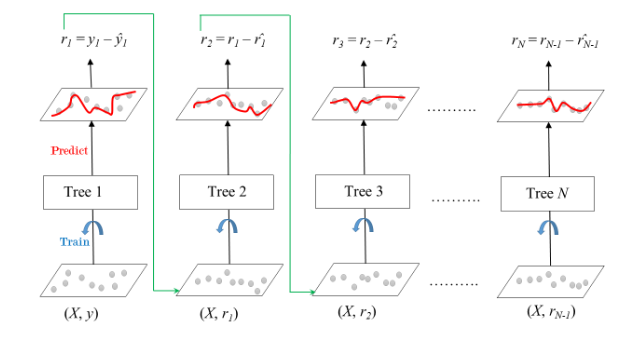
Gradient Boosted Trees for Regression
The ensemble consists of M trees. Tree1 is trained using the feature matrix X and the labels y. The predictions labeled y1(hat) are used to determine the training set residual errors r1. Tree2 is then trained using the feature matrix X and the residual errors r1 of Tree1 as labels. The predicted results r1(hat) are then used to determine the residual r2. The process is repeated until all the M trees forming the ensemble are trained. There is an important parameter used in this technique known as Shrinkage. Shrinkage refers to the fact that the prediction of each tree in the ensemble is shrunk after it is multiplied by the learning rate (eta) which ranges between 0 to 1. There is a trade-off between eta and the number of estimators, decreasing learning rate needs to be compensated with increasing estimators in order to reach certain model performance. Since all trees are trained now, predictions can be made. Each tree predicts a label and the final prediction is given by the formula,
y(pred) = y1 + (eta * r1) + (eta * r2) + ....... + (eta * rN)
Difference between Adaboost and Gradient Boosting
The difference between AdaBoost and gradient boosting are as follows:
AdaBoost
| Gradient Boosting
|
| During each iteration in AdaBoost, the weights of incorrectly classified samples are increased, so that the next weak learner focuses more on these samples. | Gradient Boosting updates the weights by computing the negative gradient of the loss function with respect to the predicted output. |
| AdaBoost uses simple decision trees with one split known as the decision stumps of weak learners. | Gradient Boosting can use a wide range of base learners, such as decision trees, and linear models. |
| AdaBoost is more susceptible to noise and outliers in the data, as it assigns high weights to misclassified samples | Gradient Boosting is generally more robust, as it updates the weights based on the gradients, which are less sensitive to outliers. |
Gradient Boosting Algorithm
Step 1:
Let’s assume X, and Y are the input and target having N samples. Our goal is to learn the function f(x) that maps the input features X to the target variables y. It is boosted trees i.e the sum of trees.
The loss function is the difference between the actual and the predicted variables.

Step 2: We want to minimize the loss function L(f) with respect to f.

If our gradient boosting algorithm is in M stages then To improve the  the algorithm can add some new estimator as
the algorithm can add some new estimator as  having
having 

Step 3: Steepest Descent
For M stage gradient boosting, The steepest Descent finds  where
where  is constant and known as step length and
is constant and known as step length and  is the gradient of loss function L(f)
is the gradient of loss function L(f)
![g_{im} =-\left[\frac{\partial L(y_i,f(x_i))}{\partial f(x_i)} \right]_{f(x_i)=f_{m-1}(x_i)}](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-34e2d0d2bd78a677323f67318cdd8ec8_l3.png "Rendered by QuickLaTeX.com")
Step 4: Solution
The gradient Similarly for M trees:
![f_m (x) = f_{m-1} (x) + \left(\underset{h_{m}\epsilon H}{argmin} \left[ \sum ^{N}_{i=1}L(y_i,f_{m-1}(x_i)+h_m(x_i)) \right]\right)(x)](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-fcdbe213e0341eba3ea124845fa342b0_l3.png "Rendered by QuickLaTeX.com")
The current solution will be

Example: 1 Classifiaction
Steps:
- Import the necessary libraries
- Setting SEED for reproducibility
- Load the digit dataset and split it into train and test.
- Instantiate Gradient Boosting classifier and fit the model.
- Predict the test set and compute the accuracy score.
Python3
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_digits
SEED = 23
X, y = load_digits(return_X_y=True)
train_X, test_X, train_y, test_y = train_test_split(X, y,
test_size = 0.25,
random_state = SEED)
gbc = GradientBoostingClassifier(n_estimators=300,
learning_rate=0.05,
random_state=100,
max_features=5 )
gbc.fit(train_X, train_y)
pred_y = gbc.predict(test_X)
acc = accuracy_score(test_y, pred_y)
print("Gradient Boosting Classifier accuracy is : {:.2f}".format(acc))
|
Output:
Gradient Boosting Classifier accuracy is : 0.98
Example: 2 Regression
Steps:
- Import the necessary libraries
- Setting SEED for reproducibility
- Load the diabetes dataset and split it into train and test.
- Instantiate Gradient Boosting Regressor and fit the model.
- Predict on the test set and compute RMSE.
python3
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_diabetes
SEED = 23
X, y = load_diabetes(return_X_y=True)
train_X, test_X, train_y, test_y = train_test_split(X, y,
test_size = 0.25,
random_state = SEED)
gbr = GradientBoostingRegressor(loss='absolute_error',
learning_rate=0.1,
n_estimators=300,
max_depth = 1,
random_state = SEED,
max_features = 5)
gbr.fit(train_X, train_y)
pred_y = gbr.predict(test_X)
test_rmse = mean_squared_error(test_y, pred_y) ** (1 / 2)
print('Root mean Square error: {:.2f}'.format(test_rmse))
|
Output:
Root mean Square error: 56.39
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...