ML | ECLAT Algorithm
Last Updated :
12 Jun, 2019
Prerequisites: Apriori Algorithm
The ECLAT algorithm stands for Equivalence Class Clustering and bottom-up Lattice Traversal. It is one of the popular methods of Association Rule mining. It is a more efficient and scalable version of the Apriori algorithm. While the Apriori algorithm works in a horizontal sense imitating the Breadth-First Search of a graph, the ECLAT algorithm works in a vertical manner just like the Depth-First Search of a graph. This vertical approach of the ECLAT algorithm makes it a faster algorithm than the Apriori algorithm.
How the algorithm work? :
The basic idea is to use Transaction Id Sets(tidsets) intersections to compute the support value of a candidate and avoiding the generation of subsets which do not exist in the prefix tree. In the first call of the function, all single items are used along with their tidsets. Then the function is called recursively and in each recursive call, each item-tidset pair is verified and combined with other item-tidset pairs. This process is continued until no candidate item-tidset pairs can be combined.
Let us now understand the above stated working with an example:-
Consider the following transactions record:-
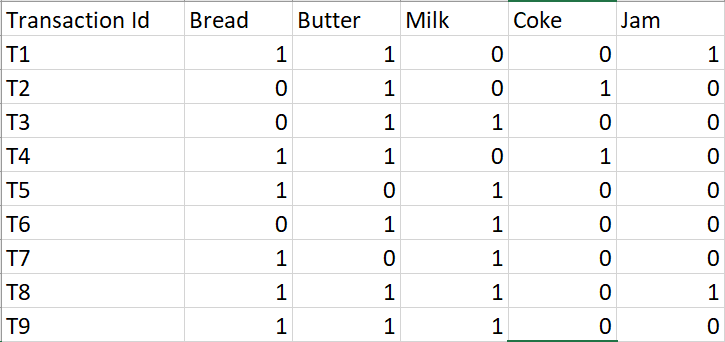
The above-given data is a boolean matrix where for each cell (i, j), the value denotes whether the j’th item is included in the i’th transaction or not. 1 means true while 0 means false.
We now call the function for the first time and arrange each item with it’s tidset in a tabular fashion:-
k = 1, minimum support = 2
| Item |
Tidset |
| Bread |
{T1, T4, T5, T7, T8, T9} |
| Butter |
{T1, T2, T3, T4, T6, T8, T9} |
| Milk |
{T3, T5, T6, T7, T8, T9} |
| Coke |
{T2, T4} |
| Jam |
{T1, T8} |
We now recursively call the function till no more item-tidset pairs can be combined:-
k = 2
| Item |
Tidset |
| {Bread, Butter} |
{T1, T4, T8, T9} |
| {Bread, Milk} |
{T5, T7, T8, T9} |
| {Bread, Coke} |
{T4} |
| {Bread, Jam} |
{T1, T8} |
| {Butter, Milk} |
{T3, T6, T8, T9} |
| {Butter, Coke} |
{T2, T4} |
| {Butter, Jam} |
{T1, T8} |
| {Milk, Jam} |
{T8} |
k = 3
| Item |
Tidset |
| {Bread, Butter, Milk} |
{T8, T9} |
| {Bread, Butter, Jam} |
{T1, T8} |
k = 4
| Item |
Tidset |
| {Bread, Butter, Milk, Jam} |
{T8} |
We stop at k = 4 because there are no more item-tidset pairs to combine.
Since minimum support = 2, we conclude the following rules from the given dataset:-
| Items Bought |
Recommended Products |
| Bread |
Butter |
| Bread |
Milk |
| Bread |
Jam |
| Butter |
Milk |
| Butter |
Coke |
| Butter |
Jam |
| Bread and Butter |
Milk |
| Bread and Butter |
Jam |
Advantages over Apriori algorithm:-
- Memory Requirements: Since the ECLAT algorithm uses a Depth-First Search approach, it uses less memory than Apriori algorithm.
- Speed: The ECLAT algorithm is typically faster than the Apriori algorithm.
- Number of Computations: The ECLAT algorithm does not involve the repeated scanning of the data to compute the individual support values.
Share your thoughts in the comments
Please Login to comment...