MapReduce – Combiners
Last Updated :
22 Apr, 2023
Map-Reduce is a programming model that is used for processing large-size data-sets over distributed systems in Hadoop. Map phase and Reduce Phase are the main two important parts of any Map-Reduce job. Map-Reduce applications are limited by the bandwidth available on the cluster because there is a movement of data from Mapper to Reducer.
For example, if we have 1 GBPS(Gigabits per second) of the network in our cluster and we are processing data that is in the range of hundreds of PB(Peta Bytes). Moving such a large dataset over 1GBPS takes too much time to process. The Combiner is used to solve this problem by minimizing the data that got shuffled between Map and Reduce.
In this article, we are going to cover Combiner in Map-Reduce covering all the below aspects.
- What is a combiner?
- How combiner works
- Advantage of combiners
- Disadvantage of combiner
What is a combiner?
Combiner always works in between Mapper and Reducer. The output produced by the Mapper is the intermediate output in terms of key-value pairs which is massive in size. If we directly feed this huge output to the Reducer, then that will result in increasing the Network Congestion. So to minimize this Network congestion we have to put combiner in between Mapper and Reducer. These combiners are also known as semi-reducer. It is not necessary to add a combiner to your Map-Reduce program, it is optional. Combiner is also a class in our java program like Map and Reduce class that is used in between this Map and Reduce classes. Combiner helps us to produce abstract details or a summary of very large datasets. When we process or deal with very large datasets using Hadoop Combiner is very much necessary, resulting in the enhancement of overall performance.
How does combiner work?
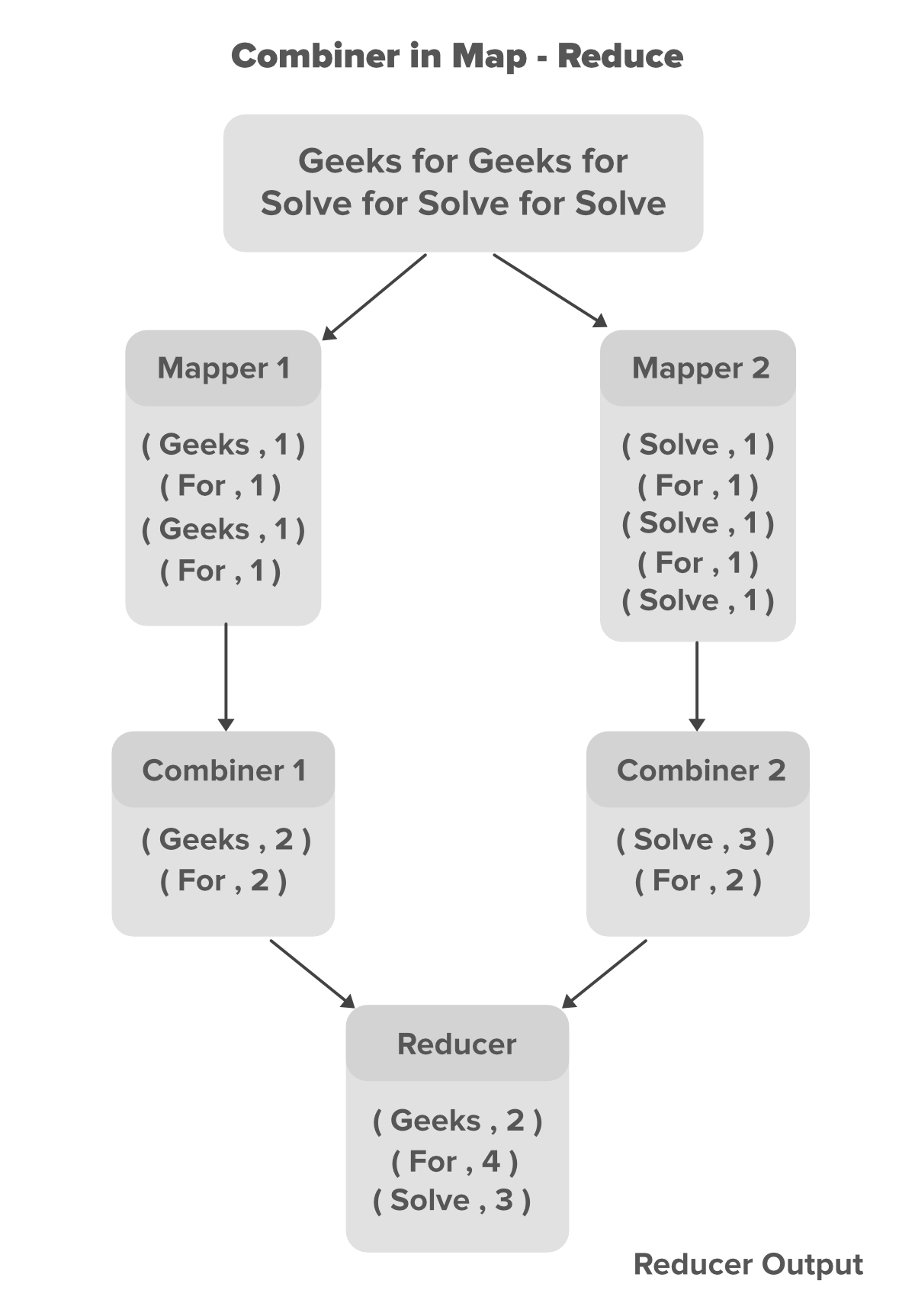
In the above example, we can see that two Mappers are containing different data. the main text file is divided into two different Mappers. Each mapper is assigned to process a different line of our data. in our above example, we have two lines of data so we have two Mappers to handle each line. Mappers are producing the intermediate key-value pairs, where the name of the particular word is key and its count is its value. For example for the data Geeks For Geeks For the key-value pairs are shown below.
// Key Value pairs generated for data Geeks For Geeks For
(Geeks,1)
(For,1)
(Geeks,1)
(For,1)
The key-value pairs generated by the Mapper are known as the intermediate key-value pairs or intermediate output of the Mapper. Now we can minimize the number of these key-value pairs by introducing a combiner for each Mapper in our program. In our case, we have 4 key-value pairs generated by each of the Mapper. since these intermediate key-value pairs are not ready to directly feed to Reducer because that can increase Network congestion so Combiner will combine these intermediate key-value pairs before sending them to Reducer. The combiner combines these intermediate key-value pairs as per their key. For the above example for data Geeks For Geeks For the combiner will partially reduce them by merging the same pairs according to their key value and generate new key-value pairs as shown below.
// Partially reduced key-value pairs with combiner
(Geeks,2)
(For,2)
With the help of Combiner, the Mapper output got partially reduced in terms of size(key-value pairs) which now can be made available to the Reducer for better performance. Now the Reducer will again Reduce the output obtained from combiners and produces the final output that is stored on HDFS(Hadoop Distributed File System).
Advantage of combiners
- Reduces the time taken for transferring the data from Mapper to Reducer.
- Reduces the size of the intermediate output generated by the Mapper.
- Improves performance by minimizing Network congestion.
- Reduces the workload on the Reducer: Combiners can help reduce the amount of data that needs to be processed by the Reducer. By performing some aggregation or reduction on the data in the Mapper phase itself, combiners can reduce the number of records that are passed on to the Reducer, which can help improve overall performance.
- Improves fault tolerance: Combiners can also help improve fault tolerance in MapReduce. In case of a node failure, the MapReduce job can be re-executed from the point of failure. Since combiners perform some of the aggregation or reduction tasks in the Mapper phase itself, this reduces the amount of work that needs to be re-executed, which can help improve fault tolerance.
- Improves scalability: By reducing the amount of data that needs to be transferred between the Mapper and Reducer, combiners can help improve the scalability of MapReduce jobs. This is because the amount of network bandwidth required for transferring data is reduced, which can help prevent network congestion and improve overall performance.
- Helps optimize MapReduce jobs: Combiners can be used to optimize MapReduce jobs by performing some preliminary data processing before the data is sent to the Reducer. This can help reduce the amount of processing required by the Reducer, which can help improve performance and reduce overall processing time.
Disadvantage of combiners
- The intermediate key-value pairs generated by Mappers are stored on Local Disk and combiners will run later on to partially reduce the output which results in expensive Disk Input-Output.
- The map-Reduce job can not depend on the function of the combiner because there is no such guarantee in its execution.
- Increased resource usage: Combiners can increase the resource usage of MapReduce jobs since they require additional CPU and memory resources to perform their operations. This can be especially problematic in large-scale MapReduce jobs that process huge amounts of data.
- Combiners may not always be effective: While combiners can help reduce the amount of data transferred between the Mapper and Reducer, they may not always be effective in doing so. This is because the effectiveness of combiners depends on the data being processed and the operations being performed. In some cases, using combiners may actually increase the amount of data transferred, which can reduce overall performance.
- Combiners can introduce data inconsistencies: Since combiners perform partial reductions on the data, they can introduce inconsistencies in the output if they are not implemented correctly. This can be especially problematic if the combiner performs operations that are not associative or commutative, which can lead to incorrect results.
- Increased complexity: Combiners can add complexity to MapReduce jobs since they require additional logic to be implemented in the code. This can make the code more difficult to maintain and debug, especially if the combiner logic is complex.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...