Longest Common Prefix using Divide and Conquer Algorithm
Last Updated :
01 Jul, 2022
Given a set of strings, find the longest common prefix.
Examples:
Input : {“geeksforgeeks”, “geeks”, “geek”, “geezer”}
Output : "gee"
Input : {"apple", "ape", "april"}
Output : "ap"
We have discussed word by word matching and character by character matching algorithms.
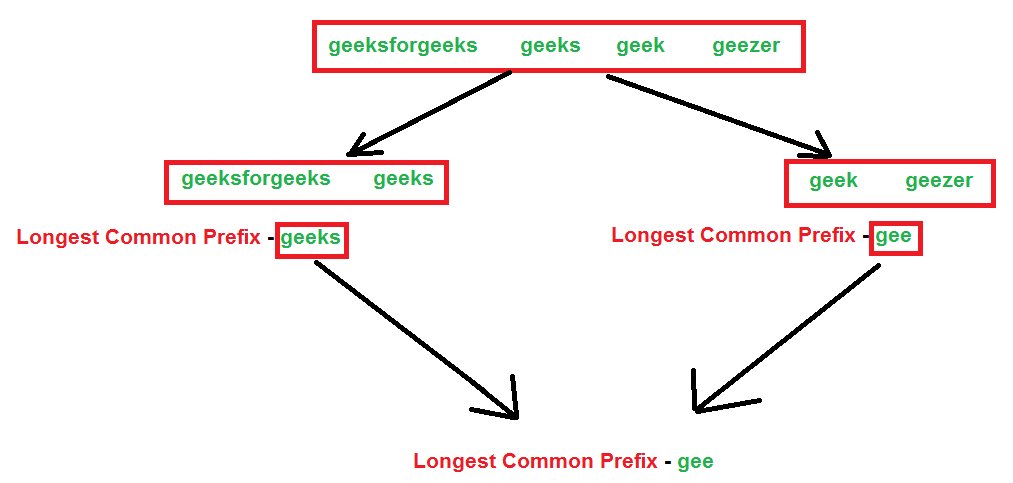
In this algorithm, a divide and conquer approach is discussed. We first divide the arrays of string into two parts. Then we do the same for left part and after that for the right part. We will do it until and unless all the strings become of length 1. Now after that, we will start conquering by returning the common prefix of the left and the right strings.
The algorithm will be clear using the below illustration. We consider our strings as – “geeksforgeeks”, “geeks”, “geek”, “geezer”.
Below is the implementation.
C++
#include<bits/stdc++.h>
using namespace std;
string commonPrefixUtil(string str1, string str2)
{
string result;
int n1 = str1.length(), n2 = str2.length();
for (int i=0, j=0; i<=n1-1&&j<=n2-1; i++,j++)
{
if (str1[i] != str2[j])
break;
result.push_back(str1[i]);
}
return (result);
}
string commonPrefix(string arr[], int low, int high)
{
if (low == high)
return (arr[low]);
if (high > low)
{
int mid = low + (high - low) / 2;
string str1 = commonPrefix(arr, low, mid);
string str2 = commonPrefix(arr, mid+1, high);
return (commonPrefixUtil(str1, str2));
}
}
int main()
{
string arr[] = {"geeksforgeeks", "geeks",
"geek", "geezer"};
int n = sizeof (arr) / sizeof (arr[0]);
string ans = commonPrefix(arr, 0, n-1);
if (ans.length())
cout << "The longest common prefix is "
<< ans;
else
cout << "There is no common prefix";
return (0);
}
|
Java
class GFG {
static String commonPrefixUtil(String str1, String str2) {
String result = "";
int n1 = str1.length(), n2 = str2.length();
for (int i = 0, j = 0; i <= n1 - 1 &&
j <= n2 - 1; i++, j++) {
if (str1.charAt(i) != str2.charAt(j)) {
break;
}
result += str1.charAt(i);
}
return (result);
}
static String commonPrefix(String arr[], int low, int high) {
if (low == high) {
return (arr[low]);
}
if (high > low) {
int mid = low + (high - low) / 2;
String str1 = commonPrefix(arr, low, mid);
String str2 = commonPrefix(arr, mid + 1, high);
return (commonPrefixUtil(str1, str2));
}
return null;
}
public static void main(String[] args) {
String arr[] = {"geeksforgeeks", "geeks",
"geek", "geezer"};
int n = arr.length;
String ans = commonPrefix(arr, 0, n - 1);
if (ans.length() != 0) {
System.out.println("The longest common prefix is "
+ ans);
} else {
System.out.println("There is no common prefix");
}
}
}
|
Python3
def commonPrefixUtil(str1, str2):
result = ""
n1, n2 = len(str1), len(str2)
i, j = 0, 0
while i <= n1 - 1 and j <= n2 - 1:
if str1[i] != str2[j]:
break
result += str1[i]
i, j = i + 1, j + 1
return result
def commonPrefix(arr, low, high):
if low == high:
return arr[low]
if high > low:
mid = low + (high - low) // 2
str1 = commonPrefix(arr, low, mid)
str2 = commonPrefix(arr, mid + 1, high)
return commonPrefixUtil(str1, str2)
if __name__ == "__main__":
arr = ["geeksforgeeks", "geeks",
"geek", "geezer"]
n = len(arr)
ans = commonPrefix(arr, 0, n - 1)
if len(ans):
print("The longest common prefix is", ans)
else:
print("There is no common prefix")
|
C#
using System;
class GFG
{
static string commonPrefixUtil(string str1,
string str2)
{
string result = "";
int n1 = str1.Length,
n2 = str2.Length;
for (int i = 0, j = 0;
i <= n1 - 1 && j <= n2 - 1;
i++, j++)
{
if (str1[i] != str2[j])
break;
result += str1[i];
}
return (result);
}
static string commonPrefix(string []arr,
int low, int high)
{
if (low == high)
return (arr[low]);
if (high > low)
{
int mid = low + (high - low) / 2;
string str1 = commonPrefix(arr, low, mid);
string str2 = commonPrefix(arr, mid + 1, high);
return (commonPrefixUtil(str1, str2));
}
return null;
}
public static void Main()
{
String []arr = {"geeksforgeeks", "geeks",
"geek", "geezer"};
int n = arr.Length;
String ans = commonPrefix(arr, 0, n - 1);
if (ans.Length!= 0)
{
Console.Write("The longest common " +
"prefix is " + ans);
}
else
{
Console.Write("There is no common prefix");
}
}
}
|
Javascript
<script>
function commonPrefixUtil(str1, str2)
{
let result = "";
let n1 = str1.length, n2 = str2.length;
for(let i = 0, j = 0; i <= n1 - 1 &&
j <= n2 - 1; i++, j++)
{
if (str1[i] != str2[j])
{
break;
}
result += str1[i];
}
return (result);
}
function commonPrefix(arr, low, high)
{
if (low == high)
{
return (arr[low]);
}
if (high > low)
{
let mid = low + Math.floor((high - low) / 2);
let str1 = commonPrefix(arr, low, mid);
let str2 = commonPrefix(arr, mid + 1, high);
return (commonPrefixUtil(str1, str2));
}
return null;
}
let arr = [ "geeksforgeeks", "geeks",
"geek", "geezer" ];
let n = arr.length;
let ans = commonPrefix(arr, 0, n - 1);
if (ans.length != 0)
{
document.write(
"The longest common prefix is " + ans);
}
else
{
document.write(
"There is no common prefix");
}
</script>
|
Output
The longest common prefix is gee
Time Complexity: Since we are iterating through all the characters of all the strings, so we can say that the time complexity is O(N M) where,
N = Number of strings
M = Length of the largest string string
Auxiliary Space: To store the longest prefix string we are allocating space which is O(M Log N).
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...