Load Balancer – System Design Interview Question
Last Updated :
14 Feb, 2024
When a website becomes extremely popular, the traffic on that website increases, and the load on a single server also increases. The concurrent traffic overloads the single server and the website becomes slower for the users. To meet the request of these high volumes of data and to return the correct response in a fast and reliable manner, we need to scale the server. This can be done by adding more servers to the network and distributing all the requests across these servers.
.webp)
Important Topics for the Load Balancer – System Design Interview Question
A load balancer is a networking device or software application that distributes and balances the incoming traffic among the servers to provide high availability, efficient utilization of servers, and high performance.
- Load balancers are highly used in cloud computing domains, data centers, and large-scale web applications where traffic flow needs to be managed.
- The primary goal of using a load balancer is, not to overburden with huge incoming traffic which may lead to server crashes or high latency.
2. What will happen if there is No Load Balancer?
Before understanding how a load balancer works, let’s understand what problem will occur without the load balancer through an example.
Consider a scenario where an application is running on a single server and the client connects to that server directly without load balancing.
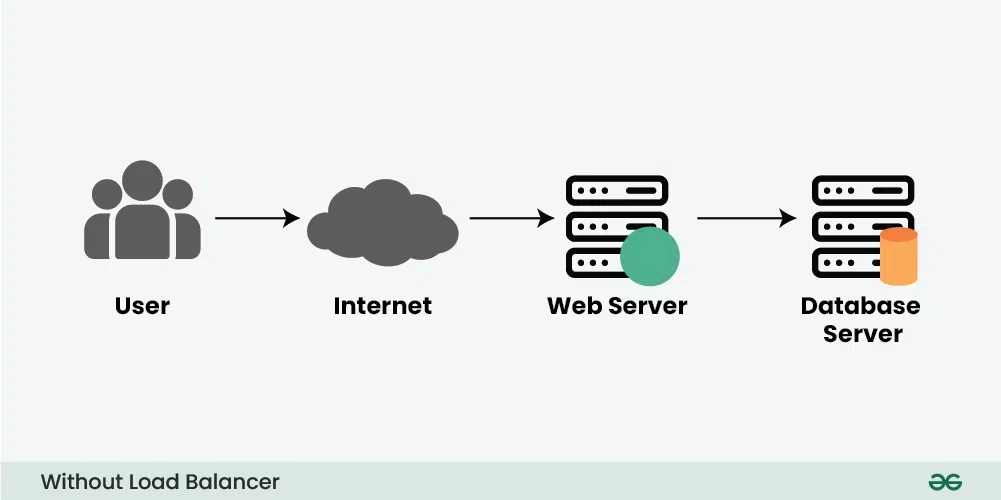
There are two main problems with this model:
- Single Point of Failure:
- If the server goes down or something happens to the server the whole application will be interrupted and it will become unavailable for the users for a certain period. It will create a bad experience for users which is unacceptable for service providers.
- Overloaded Servers:
- There will be a limitation on the number of requests that a web server can handle. If the business grows and the number of requests increases the server will be overloaded.
- To solve the increasing number of requests we need to add a few more servers and we need to distribute the requests to the cluster of servers.
Lets understand how Load Balancer works through the above discussed example:
To solve the above issue and to distribute the number of requests we can add a load balancer in front of the web servers and allow our services to handle any number of requests by adding any number of web servers in the network.
- We can spread the request across multiple servers.
- For some reason, if one of the servers goes offline the service will be continued.
- Also, the latency on each request will go down because each server is not bottlenecked on RAM/Disk/CPU anymore.

Load balancers minimize server response time and maximize throughput. Load balancer ensures high availability and reliability by sending requests only to online servers Load balancers do continuous health checks to monitor the server’s capability of handling the request. Depending on the number of requests or demand load balancers add or remove the number of servers.
4. Where Are Load Balancers Typically Placed?
Below is the image where a load balancer can be placed…
.webp)
- In between the client application/user and the server
- In between the server and the application/job servers
- In between the application servers and the cache servers
- In between the cache servers the database servers
5.1. Types of Load Balancer – Based on Configurations
There are mainly three typers of load balancers based on configurations:
1. Software Load Balancers
Software load balancers are applications or components that run on general-purpose servers. They are implemented in software, making them flexible and adaptable to various environments.
2. Hardware Load Balancers
As the name suggests we use a physical appliance to distribute the traffic across the cluster of network servers. These load balancers are also known as Layer 4-7 Routers and these are capable of handling all kinds of HTTP, HTTPS, TCP, and UDP traffic.
- These load balancers are expensive to acquire and configure, which is the reason a lot of service providers use them only as the first entry point for user requests.
- Later the internal software load balancers are used to redirect the data behind the infrastructure wall.
3. Virtual Load Balancers
A virtual load balancer is a type of load balancing solution implemented as a virtual machine (VM) or software instance within a virtualized environment ,such as data centers utilizing virtualization technologies like VMware, Hyper-V, or KVM.. It plays a crucial role in distributing incoming network traffic across multiple servers or resources to ensure efficient utilization of resources, improve response times, and prevent server overload.
There are mainly three typers of load balancers based on functions:
1. Layer 4 (L4) Load Balancer
Layer-4 load balancers operate at the transport layer of the OSI model. They make forwarding decisions based on information available in network layer protocols (such as IP addresses and port numbers).
2. Layer 7 (L7) Load Balancer
Layer-7 load balancers operate at the application layer of the OSI model. They can make load balancing decisions based on content, including information such as URLs, HTTP headers, or cookies.
3. Global Server Load Balancing (GSLB)
GSLB stands for Global Server Load Balancer. This type of load balancer goes beyond the traditional local load balancing and is designed for distributing traffic across multiple data centers or geographically distributed servers. It takes into account factors such as server proximity, server health, and geographic location to intelligently distribute traffic across multiple locations.
Further Read: Layer-4 vs. Layer-7 vs. GSLB
We need a load-balancing algorithm to decide which request should be redirected to which backend server. The different system uses different ways to select the servers from the load balancer. Companies use varieties of load-balancing algorithm techniques depending on the configuration. Some of the common load-balancing algorithms are given below:
1. Round Robin
The Round Robin algorithm is a simple static load balancing approach in which requests are distributed across the servers in a sequential or rotational manner. It is easy to implement but it doesn’t consider the load already on a server so there is a risk that one of the servers receives a lot of requests and becomes overloaded.
2. Weighted Round Robin
The Weighted Round Robin algorithm is also a static load balancing approach which is much similar to the round-robin technique. The only difference is, that each of the resources in a list is provided a weighted score. Depending on the weighted score the request is distributed to these servers.
3. Source IP Hash
The Source IP Hash cLoad Balancing Algorithm is a static method used in network load balancing to distribute incoming requests among a set of servers based on the hash value of the source IP address. This algorithm aims to ensure that requests originating from the same source IP address are consistently directed to the same server.
4. Least Connection Method
The Least Connections algorithm is a dynamic load balancing approach that assigns new requests to the server with the fewest active connections. The idea is to distribute incoming workloads in a way that minimizes the current load on each server, aiming for a balanced distribution of connections across all available resources.
5. Least Response Time Method
The Least Response method is a dynamic load balancing approach that aims to minimize response times by directing new requests to the server with the quickest response time.
7. How to Use Load Balancing During System Design Interviews?
In your system design interview, you’ll be asked some sort of scalability question where you’ll have to explain how load balancers help distribute the traffic and how it ensures scalability and availability of services in your application. The overall concept that you need to keep in mind from this article is…
- A load balancer enables elastic scalability which improves the performance and throughput of data. It allows you to keep many copies of data (redundancy) to ensure the availability of the system. In case a server goes down or fails you’ll have the backup to restore the services.
- Load balancers can be placed at any software layer.
- Many companies use both hardware and software to implement load balancers, depending on the different scale points in their system.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...