Little and Big Endian Mystery
Last Updated :
09 Jan, 2024
What are these?
Little and big endian are two ways of storing multibyte data-types ( int, float, etc). In little endian machines, last byte of binary representation of the multibyte data-type is stored first. On the other hand, in big endian machines, first byte of binary representation of the multibyte data-type is stored first.
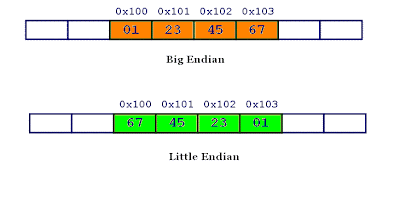
Suppose integer is stored as 4 bytes (For those who are using DOS-based compilers such as C++ 3.0, integer is 2 bytes) then a variable x with value 0x01234567 will be stored as following.
How to see memory representation of multibyte data types on your machine?
Here is a sample C code that shows the byte representation of int, float and pointer.
C++
#include <stdio.h>
void show_mem_rep(char *start, int n)
{
int i;
for (i = 0; i < n; i++)
printf(" %.2x", start[i]);
printf("\n");
}
int main()
{
int i = 0x01234567;
show_mem_rep((char *)&i, sizeof(i));
getchar();
return 0;
}
|
C
#include <stdio.h>
void show_mem_rep(char *start, int n)
{
int i;
for (i = 0; i < n; i++)
printf(" %.2x", start[i]);
printf("\n");
}
int main()
{
int i = 0x01234567;
show_mem_rep((char *)&i, sizeof(i));
getchar();
return 0;
}
|
Java
import java.nio.ByteBuffer;
public class MemoryRepresentation {
public static void main(String[] args) {
int i = 0x01234567;
byte[] reversedBytes = reverseArray(ByteBuffer.allocate(4).putInt(i).array());
showMemRep(reversedBytes);
}
public static void showMemRep(byte[] data) {
for (byte b : data) {
System.out.printf("%02x ", b & 0xFF);
}
System.out.println();
}
public static byte[] reverseArray(byte[] array) {
byte[] reversed = new byte[array.length];
for (int i = 0; i < array.length; i++) {
reversed[i] = array[array.length - 1 - i];
}
return reversed;
}
}
|
Python3
import ctypes
def show_mem_rep(start, n):
arr = (ctypes.c_ubyte * n).from_address(ctypes.addressof(start))
for i in range(n):
print(hex(arr[i])[2:].rjust(2, "0"), end=" ")
print()
if __name__ == "__main__":
i = 0x01234567
i_bytes_le = i.to_bytes(ctypes.sizeof(ctypes.c_int), byteorder="little")
i_bytes_be = i.to_bytes(ctypes.sizeof(ctypes.c_int), byteorder="big")
buf_le = ctypes.create_string_buffer(i_bytes_le)
buf_be = ctypes.create_string_buffer(i_bytes_be)
print("Little Endian: ", end="")
show_mem_rep(buf_le, ctypes.sizeof(ctypes.c_int))
print("Big Endian: ", end="")
show_mem_rep(buf_be, ctypes.sizeof(ctypes.c_int))
|
C#
using System;
class Program
{
static void Main(string[] args)
{
int i = 0x01234567;
ShowMemRep(BitConverter.GetBytes(i));
Console.ReadLine();
}
static void ShowMemRep(byte[] bytes)
{
for (int i = 0; i < bytes.Length; i++)
{
Console.Write(" {0:X2}", bytes[i]);
}
Console.WriteLine();
}
}
|
Javascript
function show_mem_rep(start, n) {
for (let i = 0; i < n; i++) {
console.log(` ${start[i].toString(16).padStart(2, '0')}`);
}
console.log("\n");
}
function main() {
let i = 0x01234567;
let byteArray = new Uint8Array(new Uint32Array([i]).buffer);
show_mem_rep(byteArray, byteArray.length);
}
main();
|
Time Complexity: O(1)
Auxiliary Space: O(1)
When above program is run on little endian machine, gives “67 45 23 01” as output, while if it is run on big endian machine, gives “01 23 45 67” as output.
Is there a quick way to determine endianness of your machine?
There are n no. of ways for determining endianness of your machine. Here is one quick way of doing the same.
C++
#include <bits/stdc++.h>
using namespace std;
int main()
{
unsigned int i = 1;
char *c = (char*)&i;
if (*c)
cout<<"Little endian";
else
cout<<"Big endian";
return 0;
}
|
C
#include <stdio.h>
int main()
{
unsigned int i = 1;
char *c = (char*)&i;
if (*c)
printf("Little endian");
else
printf("Big endian");
getchar();
return 0;
}
|
Java
public class EndiannessCheck {
public static void main(String[] args) {
int i = 1;
byte[] byteArray = toByteArray(i);
if (byteArray[0] == 1) {
System.out.println("Little endian");
} else {
System.out.println("Big endian");
}
}
private static byte[] toByteArray(int value) {
byte[] byteArray = new byte[4];
for (int i = 0; i < 4; i++) {
byteArray[i] = (byte) (value >>> (i * 8));
}
return byteArray;
}
}
|
Python3
import sys
def check_endianess():
i = 1
c = bytearray(i.to_bytes(4, sys.byteorder))
if c[0]:
print("Little endian")
else:
print("Big endian")
check_endianess()
|
C#
using System;
class Program
{
static void Main(string[] args)
{
uint i = 1;
byte[] bytes = BitConverter.GetBytes(i);
if (bytes[0] != 0)
{
Console.WriteLine("Little endian");
}
else
{
Console.WriteLine("Big endian");
}
}
}
|
Javascript
let buffer = new ArrayBuffer(4);
let view = new DataView(buffer);
view.setUint32(0, 1);
if (view.getUint8(0) === 1) {
console.log("Little endian");
} else {
console.log("Big endian");
}
|
Time Complexity: O(1)
Auxiliary Space: O(1)
In the above program, a character pointer c is pointing to an integer i. Since size of character is 1 byte when the character pointer is de-referenced it will contain only first byte of integer. If machine is little endian then *c will be 1 (because last byte is stored first) and if the machine is big endian then *c will be 0.
Does endianness matter for programmers?
Most of the times compiler takes care of endianness, however, endianness becomes an issue in following cases.
It matters in network programming: Suppose you write integers to file on a little endian machine and you transfer this file to a big-endian machine. Unless there is little endian to big endian transformation, big endian machine will read the file in reverse order. You can find such a practical example here.
Standard byte order for networks is big endian, also known as network byte order. Before transferring data on network, data is first converted to network byte order (big endian).
Sometimes it matters when you are using type casting, below program is an example.
C++
#include <iostream>
using namespace std;
int main() {
unsigned char arr[2] = {0x01, 0x00};
unsigned short int x = *(unsigned short int *) arr;
cout << x << endl;
cin.get();
return 0;
}
|
c
#include <stdio.h>
int main()
{
unsigned char arr[2] = {0x01, 0x00};
unsigned short int x = *(unsigned short int *) arr;
printf("%d", x);
getchar();
return 0;
}
|
Java
public class Main {
public static void main(String[] args) {
byte[] arr = {(byte) 0x01, (byte) 0x00};
short x = (short)((arr[1] << 8) | (arr[0] & 0xFF));
System.out.println(x);
}
}
|
Python
import struct
arr = bytearray([0x01, 0x00])
x = struct.unpack('<H', arr)[0]
print(x)
|
C#
using System;
class Program
{
static void Main()
{
byte[] arr = { 0x01, 0x00 };
ushort x = BitConverter.ToUInt16(arr, 0);
Console.WriteLine(x);
Console.ReadLine();
}
}
|
Javascript
const buffer = new ArrayBuffer(2);
const view = new DataView(buffer);
view.setUint8(0, 0x01);
view.setUint8(1, 0x00);
const x = view.getUint16(0, true);
console.log(x);
|
Time Complexity: O(1)
Auxiliary Space: O(1)
In the above program, a char array is typecasted to an unsigned short integer type. When I run above program on little endian machine, I get 1 as output, while if I run it on a big endian machine I get 256. To make programs endianness independent, above programming style should be avoided.
What are bi-endians?
Bi-endian processors can run in both modes little and big endian.
What are the examples of little, big endian and bi-endian machines ?
Intel based processors are little endians. ARM processors were little endians. Current generation ARM processors are bi-endian.
Motorola 68K processors are big endians. PowerPC (by Motorola) and SPARK (by Sun) processors were big endian. Current version of these processors are bi-endians.
Does endianness affects file formats?
File formats which have 1 byte as a basic unit are independent of endianness e.g., ASCII files. Other file formats use some fixed endianness format e.g, JPEG files are stored in big endian format.
Which one is better — little endian or big endian?
The term little and big endian came from Gulliver’s Travels by Jonathan Swift. Two groups could not agree by which end an egg should be opened -a- the little or the big. Just like the egg issue, there is no technological reason to choose one-byte ordering convention over the other, hence the arguments degenerate into bickering about sociopolitical issues. As long as one of the conventions is selected and adhered to consistently, the choice is arbitrary.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...