What is Graph Database – Introduction
Last Updated :
05 Aug, 2023
What is a Graph Database?
A graph database (GDB) is a database that uses graph structures for storing data. It uses nodes, edges, and properties instead of tables or documents to represent and store data. The edges represent relationships between the nodes. This helps in retrieving data more easily and, in many cases, with one operation. Graph databases are commonly referred to as a NoSQL.
Representation:
The graph database is based on graph theory. The data is stored in the nodes of the graph and the relationship between the data are represented by the edges between the nodes.

graph representation of data
When do we need Graph Database?
1. It solves Many-To-Many relationship problems
If we have friends of friends and stuff like that, these are many to many relationships.
Used when the query in the relational database is very complex.
2. When relationships between data elements are more important
For example- there is a profile and the profile has some specific information in it but the major selling point is the relationship between these different profiles that is how you get connected within a network.
In the same way, if there is data element such as user data element inside a graph database there could be multiple user data elements but the relationship is what is going to be the factor for all these data elements which are stored inside the graph database.
3. Low latency with large scale data
When you add lots of relationships in the relational database, the data sets are going to be huge and when you query it, the complexity is going to be more complex and it is going to be more than a usual time. However, in graph database, it is specifically designed for this particular purpose and one can query relationship with ease.
Why do Graph Databases matter? Because graphs are good at handling relationships, some databases store data in the form of a graph.
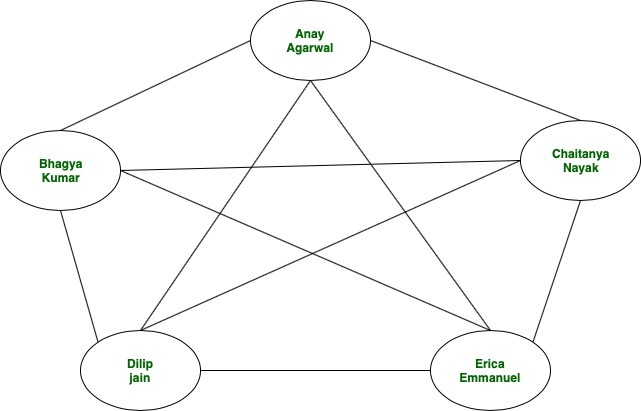
Example We have a social network in which five friends are all connected. These friends are Anay, Bhagya, Chaitanya, Dilip, and Erica. A graph database that will store their personal information may look something like this:
| id |
first name |
last name |
email |
phone |
| 1 |
Anay |
Agarwal |
anay@example.net |
555-111-5555 |
| 2 |
Bhagya |
Kumar |
bhagya@example.net |
555-222-5555 |
| 3 |
Chaitanya |
Nayak |
chaitanya@example.net |
555-333-5555 |
| 4 |
Dilip |
Jain |
dilip@example.net |
555-444-5555 |
| 5 |
Erica |
Emmanuel |
erica@example.net |
555-555-5555 |
Now, we will also a need another table to capture the friendship/relationship between users/friends. Our friendship table will look something like this:
| user_id |
friend_id |
| 1 |
2 |
| 1 |
3 |
| 1 |
4 |
| 1 |
5 |
| 2 |
1 |
| 2 |
3 |
| 2 |
4 |
| 2 |
5 |
| 3 |
1 |
| 3 |
2 |
| 3 |
4 |
| 3 |
5 |
| 4 |
1 |
| 4 |
2 |
| 4 |
3 |
| 4 |
5 |
| 5 |
1 |
| 5 |
2 |
| 5 |
3 |
| 5 |
4 |
We will avoid going deep into the Database(primary key & foreign key) theory. Instead just assume that the friendship table uses id’s of both the friends. Assume that our social network here has a feature that allows every user to see the personal information of his/her friends. So, If Chaitanya were requesting information then it would mean she needs information about Anay, Bhagya, Dilip and Erica. We will approach this problem the traditional way(Relational database). We must first identify Chaitanya’s id in the User’s table:
| id |
first name |
last name |
email |
phone |
| 3 |
Chaitanya |
Nayak |
chaitanya@example.net |
555-333-5555 |
Now, we’d look for all tuples in friendship table where the user_id is 3. Resulting relation would be something like this:
| user_id |
friend_id |
| 3 |
1 |
| 3 |
2 |
| 3 |
4 |
| 3 |
5 |
Now, let’s analyse the time taken in this Relational database approach. This will be approximately log(N) times where N represents the number of tuples in friendship table or number of relations. Here, the database maintains the rows in the order of id’s. So, in general for ‘M’ no of queries, we have a time complexity of M*log(N) Only if we had used a graph database approach, the total time complexity would have been O(N). Because, once we’ve located Cindy in the database, we have to take only a single step for finding her friends. Here is how our query would be executed:

Advantages: Frequent schema changes, managing volume of data, real-time query response time, and more intelligent data activation requirements are done by graph model.
Disadvantages: Note that graph databases aren’t always the best solution for an application. We will need to assess the needs of application before deciding the architecture.
Limitations of Graph Databases:
- Graph Databases may not be offering better choice over the NoSQL variations.
- If application needs to scale horizontally this may introduces poor performance.
- Not very efficient when it needs to update all nodes with a given parameter.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...