Introduction to Azure Cosmos DB
Last Updated :
30 Mar, 2023
CosmosDB is a NoSQL database by Azure. In this article, We’ll discuss high-level horizontal scaling, replication, partitioning, and database schema. And then we’ll dive into some of the data models that Cosmos DB supports. So, let’s get started.
Applications used to be relatively simple. We would have an app, an API layer, and a slow drip of data dropping into our database. Now occasionally, we may have needed to surface that data and lookup device information in a catalog or look up an appointment on a calendar. But often the data sat in the database until it was called on however many days, months, or even years later.
In the age of big data, where data sets have now grown from a few gigabytes to tens of gigabytes and even petabytes for some of our most demanding applications. Data is pouring into our databases and applications are demanding that data be surfaced quickly and frequently to fulfill user expectations of a personalized and fast application experience.
Now, Azure Cosmos DB has boomed as the answer to the big data demands of cloud-native applications. Because non-relational or NoSQL databases like Azure Cosmos DB scale horizontally rather than vertically, we can essentially uncap the throughput and volume of data in our database. Rather than upgrading hardware on a single node to serve requests faster, Cosmos DB distributes that work across multiple nodes so requests can be served concurrently. Scaling out verse scaling up is the biggest difference between relational databases and non-relational databases like Cosmos DB.
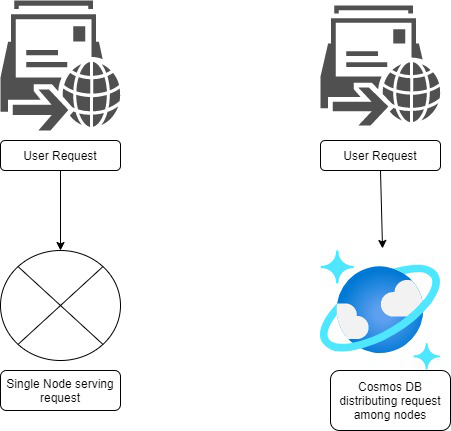
Horizontal scaling or scaling out is the consequence of two techniques: partitioning and replication. Now there are two kinds of partitions in Azure Cosmos DB: logical and physical.
A physical partition is an actual unit of storage that physically sits in the Azure region that we dictate. This is a piece of hardware holding our data somewhere in the cloud. Logical partitions are logical groups across items within our data set, and we reference these groups through something called a partition key. The partition key is important because it tells our database engine where to look for our data. Choosing the right partition key is a simple but important part of optimizing our database, and when done correctly, we can expect to see performance gains proportional to the additional number of nodes serving our requests. Put simply, partitioning our data across nodes improves database latency and throughput.
Now like with partitions, there are also two kinds of replication in Cosmos DB: replication within a region and geo-replication outside of a region. Now within a region, our data is replicated four times as a redundancy measure, improving fault tolerance. Outside of a region, our data is geo-replicated into any additional Azure regions we select resulting in higher availability. Replication within a single region increases fault tolerance. Geo-replication into additional Azure regions increases availability. Now these two techniques, replication, and partitioning are in large part what makes horizontal scaling possible.
Now what makes NoSQL attractive to modern op devs, performance and availability gains aside, are the relaxed constraints around keeping our data relational. Cosmos DB is schema-less meaning structure is not enforced on any data entering the database. Two documents in the same collection can have a completely different structure without any issue. And as a result, developers can and structurally variable data into the database and later build, change or add functionality as use for that data evolves. This combination of flexible schema and horizontal scaling is what makes NoSQL different.
Cosmos DB makes it easy to ingest and resurface high volumes of variable data without compromising on performance or availability. In addition to flexible schema, Cosmos also supports multiple data models. Cosmos has been built to be the hub for all NoSQL data types.
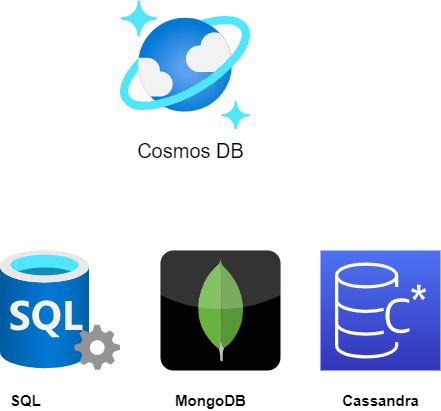
Cosmos has a SQL API with document and key-value support built-in. Documents and key-value pairs go hand in hand in most NoSQL databases because documents are just key-value pairs in which the key is a document and the value is a JSON object that we just call a document. Now to reap the performance benefits of a true key-value store, with a SQL API, we can do fast and cost-effective point reads as long as we know the document ID and partition key for the item we want to read. This is a great optimization tool for applications. The next data model, the graph data model, is accessible via the Gremlin API, which uses edges and vertices as well as a traversal to model complex systems with many to many relationships. Think of a graph as a web or a network of nodes. The API is for Mongo DB and Cassandra respectively, are created so that developers familiar with both open-source databases can work with the tools, SDKs, and drivers that they’re already used to.API for Mongo DB also leverages documents, and Cassandra API is a wide-column store, which orients data efficiently in columns instead of rows to optimize for analytics. That’s it for our first episode. Cosmos DB is our horizontally scaling, NoSQL database. Partitioning makes it fast, replication makes it available and flexible schema makes it simple to work with.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...