Importance of Hashing
Last Updated :
28 Apr, 2022
Hans Peter Luhn invented Hashing. He was a conscientious scientist in IBM researching the field of Computer Science and Information Science. There is one more famous algorithm he contributed- the Luhn algorithm. Luhn was born in Germany but after the war, he had to move to the United States as he was working in the textile field. While in the textile field he invented Lunometer which is still used. A Luminometer is a thread counting device. In 1941 he decides to join IBM as a senior research engineer. He soon got the position of manager and headed the Information Retrieval Research Department. James Perry and Malcolm Dyson brought a problem to this department of IBM in 1947. The challenge was to search chemical compounds that had been stored in coded form. This was the first Luhn was introduced to the experimenting field of information and documentation science. He used to provide solutions, but at that time the available machines also had their limitations. He then had to find new methods to overcome these limitations. And the 1950s came which was the ‘computer age’. Luhn had started spending a great deal amount of time on the challenges of the information retrieval system. In 1953 Luhn had the idea to put all the information in a bucket. He predicted that this would make searching faster. And this information can consist of numbers as well as text. Luhn’s invention was further shaped and modified by scientists of the coming generation. Hashing algorithms today have become essential, especially in cryptography, cloud service, textual tools, data-intensive research, etc. The two other great inventions of Luhn are KWIC and SDI systems. 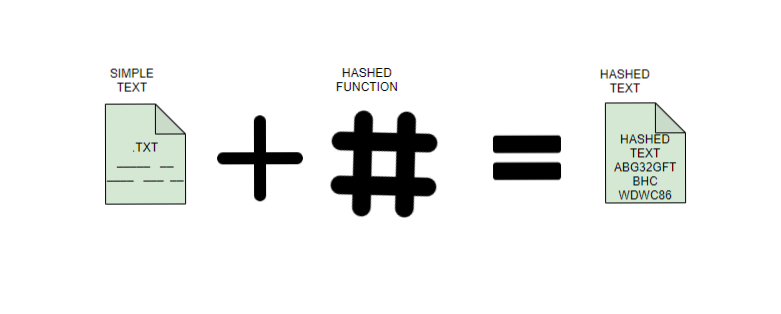
Importance of Hashing
- Hashing gives a more secure and adjustable method of retrieving data compared to any other data structure. It is quicker than searching for lists and arrays. In the very range, Hashing can recover data in 1.5 probes, anything that is saved in a tree. Hashing, unlike other data structures, doesn’t define the speed. A balance between time and space has to be maintained while hashing. There are two ways of maintaining this balance.
- Controlling speed by selecting the space to be allocated for the hash table
- Controlling space by choosing a speed of recovery
- Hashed passwords cannot be modified, stolen, or jeopardized. No well-recognized and efficient key or encryption scheme exists that can be misused. Also, there is no need to worry if a hash code is stolen since it cannot be applied anywhere else.
- Two files can be compared for equality easily through hashing. There is no need to open the two documents individually. Hashing compares them word-by-word and the computed hash value instantly tells if they are distinct. This advantage can be used for the verification of a file after it has been shifted to a new place. It is an example of SyncBack which is a file backup program.
- In DBMS, hashing is used to search the location of the data without using index structure. This method is faster to search using the short hashed key instead of the original value.
Application of Hashing:
- Password Verification
- Compiler Operation
- Rabin-Karp Algorithm
- Data Structures
- Message Digest
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...