Autoencoders are a type of neural network which generates an “n-layer” coding of the given input and attempts to reconstruct the input using the code generated. This Neural Network architecture is divided into the encoder structure, the decoder structure, and the latent space, also known as the “bottleneck”. To learn the data representations of the input, the network is trained using Unsupervised data. These compressed, data representations go through a decoding process wherein which the input is reconstructed. An autoencoder is a regression task that models an identity function.
Encoder Structure
This structure comprises a conventional, feed-forward neural network that is structured to predict the latent view representation of the input data. It is given by:

Where  represents the hidden layer 1,
represents the hidden layer 1,  represents the hidden layer 2,
represents the hidden layer 2,  represents the input of the autoencoder, and h represents the low-dimensional, data space of the input
represents the input of the autoencoder, and h represents the low-dimensional, data space of the input
Decoder Structure
This structure comprises a feed-forward neural network but the dimension of the data increases in the order of the encoder layer for predicting the input. It is given by:

Where  represents the hidden layer 1,
represents the hidden layer 1,  represents the hidden layer 2,
represents the hidden layer 2,  represents the low-dimensional, data space generated by the Encoder Structure and
represents the low-dimensional, data space generated by the Encoder Structure and  represents the reconstructed input.
represents the reconstructed input.
Latent Space Structure
This is the data representation or the low-level, compressed representation of the model’s input. The decoder structure uses this low-dimensional form of data to reconstruct the input. It is represented by 
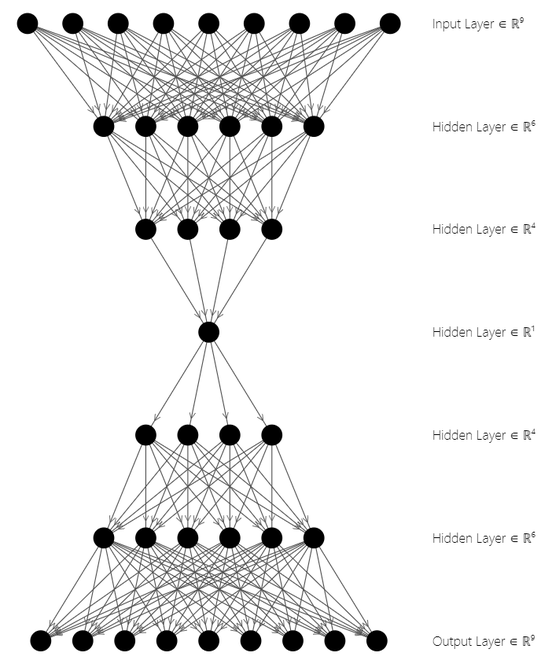
Autoencoder Architecture
In the above figure, the top three layers represent the Encoder Block while the bottom three layers represent the Decoder Block. The latent state space is at the middle of the architecture  . Autoencoders are used for image compression, feature extraction, dimensionality reduction, etc. Let’s now see the implementation.
. Autoencoders are used for image compression, feature extraction, dimensionality reduction, etc. Let’s now see the implementation.
Modules Needed
- torch: This python package provides high-level tensor computation and deep neural networks built on autograd system.
pip install torch
- torchvision: This module consists of a wide range of databases, image architectures, and transformations for computer vision
pip install torchvision
Implementation of Autoencoder in Pytorch
Step 1: Importing Modules
We will use the torch.optim and the torch.nn module from the torch package and datasets & transforms from torchvision package. In this article, we will be using the popular MNIST dataset comprising grayscale images of handwritten single digits between 0 and 9.
Python3
import torch
from torchvision import datasets
from torchvision import transforms
import matplotlib.pyplot as plt
|
Step 2: Loading the Dataset
This snippet loads the MNIST dataset into loader using DataLoader module. The dataset is downloaded and transformed into image tensors. Using the DataLoader module, the tensors are loaded and ready to be used. The dataset is loaded with Shuffling enabled and a batch size of 64.
Python3
tensor_transform = transforms.ToTensor()
dataset = datasets.MNIST(root = "./data",
train = True,
download = True,
transform = tensor_transform)
loader = torch.utils.data.DataLoader(dataset = dataset,
batch_size = 32,
shuffle = True)
|
Step 3: Create Autoencoder Class
In this coding snippet, the encoder section reduces the dimensionality of the data sequentially as given by:
28*28 = 784 ==> 128 ==> 64 ==> 36 ==> 18 ==> 9
Where the number of input nodes is 784 that are coded into 9 nodes in the latent space. Whereas, in the decoder section, the dimensionality of the data is linearly increased to the original input size, in order to reconstruct the input.
9 ==> 18 ==> 36 ==> 64 ==> 128 ==> 784 ==> 28*28 = 784
Where the input is the 9-node latent space representation and the output is the 28*28 reconstructed input.
The encoder starts with 28*28 nodes in a Linear layer followed by a ReLU layer, and it goes on until the dimensionality is reduced to 9 nodes. The decryptor uses these 9 data representations to bring back the original image by using the inverse of the encoder architecture. The decryptor architecture uses a Sigmoid Layer to range the values between 0 and 1 only.
Python3
class AE(torch.nn.Module):
def __init__(self):
super().__init__()
self.encoder = torch.nn.Sequential(
torch.nn.Linear(28 * 28, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 36),
torch.nn.ReLU(),
torch.nn.Linear(36, 18),
torch.nn.ReLU(),
torch.nn.Linear(18, 9)
)
self.decoder = torch.nn.Sequential(
torch.nn.Linear(9, 18),
torch.nn.ReLU(),
torch.nn.Linear(18, 36),
torch.nn.ReLU(),
torch.nn.Linear(36, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 28 * 28),
torch.nn.Sigmoid()
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
|
Step 4: Initializing Model
We validate the model using the Mean Squared Error function, and we use an Adam Optimizer with a learning rate of 0.1 and weight decay of 
Python3
model = AE()
loss_function = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(),
lr = 1e-1,
weight_decay = 1e-8)
|
Step 5: Create Output Generation
The output against each epoch is computed by passing as a parameter into the Model() class and the final tensor is stored in an output list. The image into (-1, 784) and is passed as a parameter to the Autoencoder class, which in turn returns a reconstructed image. The loss function is calculated using MSELoss function and plotted. In the optimizer, the initial gradient values are made to zero using zero_grad(). loss.backward() computes the grad values and stored. Using the step() function, the optimizer is updated.
The original image and the reconstructed image from the outputs list are detached and transformed into a NumPy Array for plotting the images.
Note: This snippet takes 15 to 20 mins to execute, depending on the processor type. Initialize epoch = 1, for quick results. Use a GPU/TPU runtime for faster computations.
Python3
epochs = 20
outputs = []
losses = []
for epoch in range(epochs):
for (image, _) in loader:
image = image.reshape(-1, 28*28)
reconstructed = model(image)
loss = loss_function(reconstructed, image)
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss)
outputs.append((epochs, image, reconstructed))
plt.style.use('fivethirtyeight')
plt.xlabel('Iterations')
plt.ylabel('Loss')
plt.plot(losses[-100:])
|
Output:
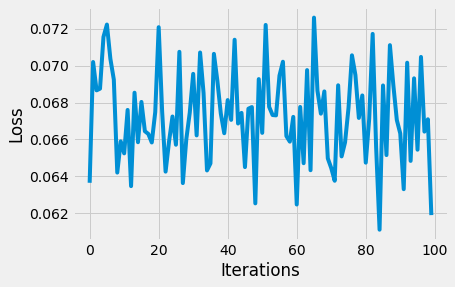
Loss function graph
Step 6: Input/Reconstructed Input to/from Autoencoder
The first input image array and the first reconstructed input image array have been plotted using plt.imshow().
Python3
for i, item in enumerate(image):
item = item.reshape(-1, 28, 28)
plt.imshow(item[0])
for i, item in enumerate(reconstructed):
item = item.reshape(-1, 28, 28)
plt.imshow(item[0])
|
Output:
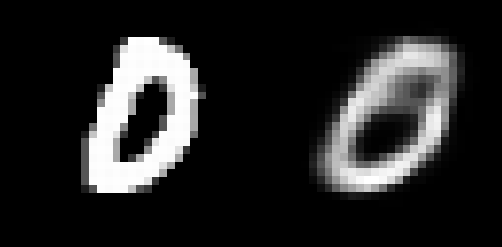
Sample Plot 1: Input image(left) and reconstructed input(right)
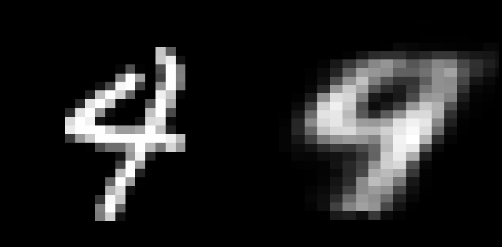
Sample Plot 2: Input image(left) and reconstructed input(right)
Although the rebuilt pictures appear to be adequate, they are extremely grainy. To enhance this outcome, extra layers and/or neurons may be added, or the autoencoder model could be built on convolutions neural network architecture. For dimensionality reduction, autoencoders are quite beneficial. However, it might also be used for data denoising and understanding a dataset’s spread.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...