How to skip rows while reading csv file using Pandas?
Last Updated :
27 Aug, 2021
Python is a good language for doing data analysis because of the amazing ecosystem of data-centric python packages. Pandas package is one of them and makes importing and analyzing data so much easier.
Here, we will discuss how to skip rows while reading csv file. We will use read_csv() method of Pandas library for this task.
Syntax: pd.read_csv(filepath_or_buffer, sep=’, ‘, delimiter=None, header=’infer’, names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression=’infer’, thousands=None, decimal=b’.’, lineterminator=None, quotechar='”‘, quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, doublequote=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)
Some useful parameters are given below :
| Parameter |
Use |
| filepath_or_buffer |
URL or Dir location of file |
| sep |
Stands for separator, default is ‘, ‘ as in csv(comma separated values) |
| index_col |
This parameter is use to make passed column as index instead of 0, 1, 2, 3…r |
| header |
This parameter is use to make passed row/s[int/int list] as header |
| use_cols |
This parameter is Only uses the passed col[string list] to make data frame |
| squeeze |
If True and only one column is passed then returns pandas series |
| skiprows |
This parameter is use to skip passed rows in new data frame |
| skipfooter |
This parameter is use to skip Number of lines at bottom of file |
For downloading the student.csv file Click Here
Method 1: Skipping N rows from the starting while reading a csv file.
Code:
Python3
import pandas as pd
df = pd.read_csv("students.csv",
skiprows = 2)
df
|
Output :
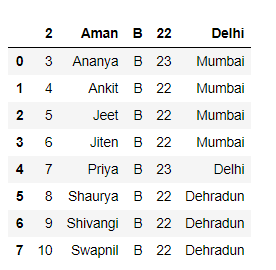
Method 2: Skipping rows at specific positions while reading a csv file.
Code:
Python3
import pandas as pd
df = pd.read_csv("students.csv",
skiprows = [0, 2, 5])
df
|
Output :
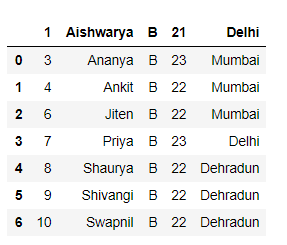
Method 3: Skipping N rows from the starting except column names while reading a csv file.
Code:
Python3
import pandas as pd
df = pd.read_csv("students.csv",
skiprows = [i for i in range(1, 3) ])
df
|
Output :
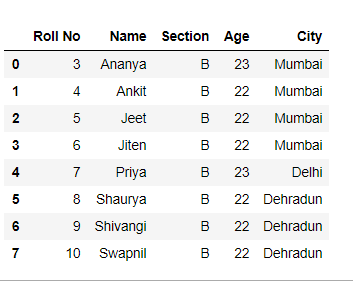
Method 4: Skip rows based on a condition while reading a csv file.
Code:
Python3
import pandas as pd
def logic(index):
if index % 3 == 0:
return True
return False
df = pd.read_csv("students.csv",
skiprows = lambda x: logic(x) )
df
|
Output :
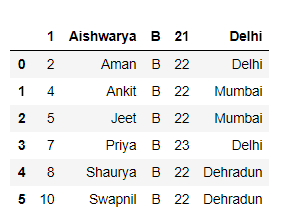
Method 5: Skip N rows from the end while reading a csv file.
Code:
Python3
import pandas as pd
df = pd.read_csv("students.csv",
skipfooter = 5,
engine = 'python')
df
|
Output :
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...