How to select the rows of a dataframe using the indices of another dataframe?
Last Updated :
27 Aug, 2021
Prerequisites:
Using Pandas module it is possible to select rows from a data frame using indices from another data frame. This article discusses that in detail. It is advised to implement all the codes in jupyter notebook for easy implementation.
Approach:
- Import module
- Create first data frame. In the example given below choice(), randint() and random() all belonging to random module are used to generate a data frame.
1) choice() – choice() is an inbuilt function in Python programming language that returns a random item from a list, tuple, or string.
Syntax: random.choice(sequence)
Parameters: Sequence is a mandatory parameter that can be a list, tuple, or string.
Returns: The choice() returns a random item.
2) randint()- This function is used to generate random numbers
Syntax : randint(start, end)
Parameters :
(start, end) : Both of them must be integer type values.
Returns :
A random integer in range [start, end] including the end points.
3) random()- Used to generate floating numbers between 0 and 1.
- Create another data frame using the random() function and randomly selecting the rows of the first dataset.
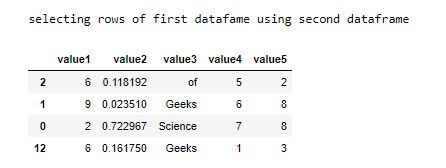
- Now we will use dataframe.loc[] function to select the row values of the first data frame using the indexes of the second data frame. Pandas DataFrame.loc[] attribute access a group of rows and columns by label(s) or a boolean array in the given DataFrame.
Syntax: DataFrame.loc
Parameter : None
Returns : Scalar, Series, DataFrame
Implementation using the above concept is given below:
Program:
Python3
import pandas as pd
import random
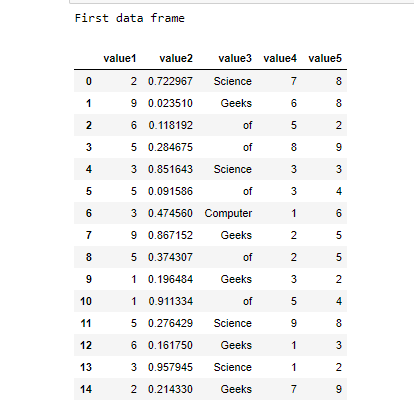
col1 = [random.randint(1, 9) for i in range(15)]
col2 = [random.random() for i in range(15)]
col3 = [random.choice(['Geeks', 'of', 'Computer', 'Science'])
for i in range(15)]
col4 = [random.randint(1, 9) for i in range(15)]
col5 = [random.randint(1, 9) for i in range(15)]
data_generated = {
'value1': col1,
'value2': col2,
'value3': col3,
'value4': col4,
'value5': col5
}
print("First data frame")
dataframe = pd.DataFrame(data_generated)
display(dataframe)
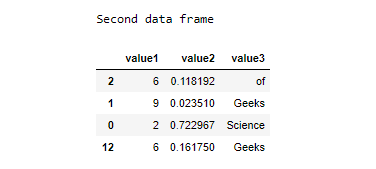
print("Second data frame")
dataframe_second = dataframe[['value1', 'value2', 'value3']].sample(n=4)
display(dataframe_second)
print("selecting rows of first dataframe using second dataframe")
display(dataframe.loc[dataframe_second.index])
|
Output:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...