How to select a subset of a DataFrame?
Last Updated :
26 Sep, 2022
In this article, we are going to discuss how to select a subset of columns and rows from a DataFrame. We are going to use the nba.csv dataset to perform all operations.
Python3
import pandas as pd
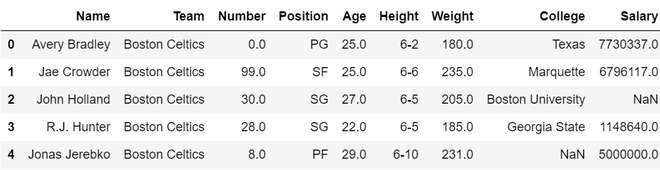
data = pd.read_csv("nba.csv")
data.head()
|
Output:
Below are various operations by using which we can select a subset for a given dataframe:
- Select a specific column from a dataframe
To select a single column, we can use a square bracket [ ]:
Python3
import pandas as pd
data = pd.read_csv("nba.csv")
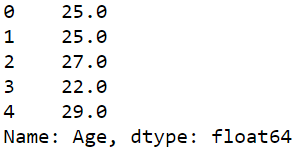
ages = data["Age"]
ages.head()
|
Output:
- Select multiple columns from a dataframe
We can pass a list of column names inside the square bracket [] to get multiple columns:
Python3
import pandas as pd
data = pd.read_csv("nba.csv")
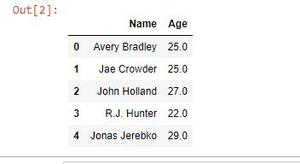
name_sex = data[["Name","Age"]]
name_sex.head()
|
Output:
- Select a subset of rows from a dataframe
To select rows of people older than 25 years in the given dataset, we can put conditions within the brackets to select specific rows depending on the condition.
Python3
import pandas as pd
data = pd.read_csv("nba.csv")
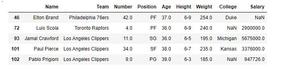
above_25 = data[data["Age"] > 35]
print(above_25.head())
|
Output:
- Select a subset of rows and columns combined
In this case, a subset of all rows and columns is made in one go, and select [] is not sufficient now. The loc or iloc operators are needed. The section before the comma is the rows you choose, and the part after the comma is the columns you want to pick by using loc or iloc. Here we select only names of people older than 25.
Python3
import pandas as pd
data = pd.read_csv("nba.csv")
adults = data.loc[data["Age"] > 25, "Name"]
print(adults.head())
|
Output:

Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...