How to Scrape Websites with Beautifulsoup and Python ?
Last Updated :
24 Apr, 2023
Have you ever wondered how much data is created on the internet every day, and what if you want to work with those data? Unfortunately, this data is not properly organized like some CSV or JSON file but fortunately, we can use web scraping to scrape the data from the internet and can use it according to our own needs. There are many ways to scrape data and one such way is using BeautifulSoup.
Before starting learning the BeautifulSoup let’s learn what is a web scraping and if we should do it or not?
What is Web Scraping?
In Layman’s term, web scraping is the process of gathering data from any website. It is just like copying and pasting the data from a website to your own file but automatically. In technical terms, Web Scripting is an automatic method to obtain large amounts of data from websites. Most of this data is unstructured data in an HTML format which is then converted into structured data in a spreadsheet or a database so that it can be used in various applications.
Note: For more information, refer to What is Web Scraping and How to Use It?
Legalization of Web Scraping
The legalization of web scraping is a sensitive topic, depending on how it is used it can either be a boon or a bane. On one hand, web scraping with good bot enables search engines to index web content, price comparison services to save customer money and value. But web scraping can be re-targeted to meet more malicious and abusive ends. Web scraping can be aligned with other forms of malicious automation, named “bad bots”, which enable other harmful activities like denial of service attacks, competitive data mining, account hijacking, data theft etc.
Now after learning the basics of web scraping let’s not waste any more of time and dive straight into the BeautifulSoup. Let’s start with the Installation.
Installation
To install Beautifulsoup on Windows, Linux, or any operating system, one would need pip package. To check how to install pip on your operating system, check out – PIP Installation – Windows || Linux. Now run the below command in the terminal.
pip install beautifulsoup4
Refer to the below articles to know more ways of installing BeautifulSoup if the above method does not work for you.
Inspecting the Website
Before scraping any website, the first thing you need to do is to know about the structure of the website. This is needed to be done in order to select the desired data from the entire page. We can do this by right clicking on the page we want to scrape and select inspect element.
Note: We will be scraping Python Programming Page for this Tutorial.

After clicking the inspect button the Developer Tools of the browser gets open. Now almost all the browsers come with the developers tools installed, and we will be using Chrome for this tutorial.

The developers tools allows to see the site’s Document Object Model (DOM). If you don’t know about DOM then don’t worry just consider the text displayed as the HTML structure of the page.
Getting the HTML of the Page
After inspecting the HTML of the page we still need to get all the HTML into our Python Code so that we can scrape the desired data. For this Python provides a module called requests. Requests library is one of the integral part of Python for making HTTP requests to a specified URL. Requests installation depends on type of operating system on eis using, the basic command anywhere would be to open a command terminal and run,
pip install requests
Now let’s make a simple GET request using the get() method.
Example:
Python3
import requests
print(r)
print(r.content)
|
Output:

Refer to the below tutorial to get detailed and well explained information about the requests module.
Parsing the HTML
After getting the HTML of the page let’s see how to parse this raw HTML code into some useful information. First of all, we will create a BeautifulSoup object by specifying the parser we want to use.
Note: BeautifulSoup library is built on the top of the HTML parsing libraries like html5lib, lxml, html.parser, etc. So BeautifulSoup object and specify the parser library can be created at the same time.
Example 1:
Python3
import requests
from bs4 import BeautifulSoup
print(r)
soup = BeautifulSoup(r.content, 'html.parser')
print(soup.prettify())
|
Output:

Example 2:
Python3
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.content, 'html.parser')
print(soup.title)
print(soup.title.name)
print(soup.title.parent.name)
|
Output:
<title>Python Programming Language - GeeksforGeeks</title>
title
meta
Finding Elements
Now, we would like to extract some useful data from the HTML content. The soup object contains all the data in the nested structure which could be programmatically extracted. The website we want to scrape contains a lot of text so now let’s scrape all those content.
First let’s inspect the webpage we want to scrape.

Finding Elements by Class
In the above image we can see that all the content of the page is under the div with class entry-content. We will store all the result found under this class.
Example:
Python3
import requests
from bs4 import BeautifulSoup
print(r)
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', class_='entry-content')
print(s)
|
Output:

In the above example we have used the find class. This class will find the given tag with the given attribute. In our case it will find all the div having class as entry-content. We have got all the content from the site but you can see that all the images and links are also scrapped. So our next task is to find only the content from the above parsed HTML.
Let’s again inspect the HTML of our website.
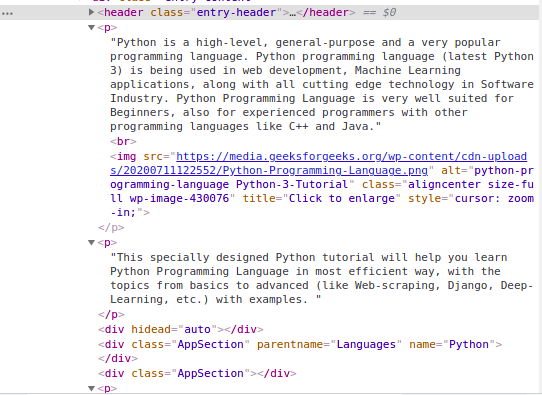
We can see that the content of the page is under the <p> tag. Now we have to find all the p tags present in this class. We can use the find_all class of the BeautifulSoup.
Example:
Python3
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', class_='entry-content')
lines = s.find_all('p')
print(lines)
|
Output:

We finally get all the content stored under the <p> tag.
Finding Elements by ID
In the above example, we have found the elements by the class name but let’s see how to find elements by id. Now for this task let’s scrape the content of the leftbar of the page. The first step is to inspect the page and see the leftbar falls under which tag.

The above image shows that the leftbar falls under the <div> tag with id as main. Now lets’s get the HTML content under this tag.
Example:
Python3
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', id= 'main')
print(s)
|
Output:

Now let’s inspect more of the page get the content of the leftbar.

We can see that the list in the leftbar is under the <ul> tag with the class as leftBarList and our task is to find all the li under this ul.
Example:
Python3
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', id= 'main')
leftbar = s.find('ul', class_='leftBarList')
content = leftbar.find_all('li')
print(content)
|
Output:

Refer to the below articles to get detailed information about finding elements.
Extracting Text from the tags
In the above examples, you must have seen that while scraping the data the tags also gets scraped but what if we want only the text without any tags. Don’t worry we will discuss the same in this section. We will be using the text property. It only prints the text from the tag. We will be using the above example and will remove all the tags from them.
Example 1: Removing the tags from the content of the page
Python3
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', class_='entry-content')
lines = s.find_all('p')
for line in lines:
print(line.text)
|
Output:

Now we have successfully scraped the content from our first website. This script will run on every system until and unless there is some changes the HTML of the webpage itself.
Example 2: Removing the tags from the content of the leftbar.
Python3
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.content, 'html.parser')
s = soup.find('div', id= 'main')
leftbar = s.find('ul', class_='leftBarList')
lines = leftbar.find_all('li')
for line in lines:
print(line.text)
|
Output:

Refer to the below articles to get detailed information about extracting text.
More Topics on BeautifulSoup
BeautifulSoup Exercises and Projects
Share your thoughts in the comments
Please Login to comment...