How to Scrape Paragraphs using Python?
Last Updated :
29 Dec, 2020
Prerequisite: Implementing Web Scraping in Python with BeautifulSoup
In this article, we are going to see how we extract all the paragraphs from the given HTML document or URL using python.
Module Needed:
- bs4: Beautiful Soup(bs4) is a Python library for pulling data out of HTML and XML files. This module does not come built-in with Python. To install this type the below command in the terminal.
pip install bs4
- requests: Requests allows you to send HTTP/1.1 requests extremely easily. This module also does not comes built-in with Python. To install this type the below command in the terminal.
pip install requests
Approach:
- Import module
- Create an HTML document and specify the ‘<p>’ tag into the code
- Pass the HTML document into the Beautifulsoup() function
- Use the ‘P’ tag to extract paragraphs from the Beautifulsoup object
- Get text from the HTML document with get_text().
Code:
Python3
from bs4 import BeautifulSoup
html_doc =
soup = BeautifulSoup(html_doc, 'html.parser')
for data in soup.find_all("p"):
print(data.get_text())
|
Output:
Welcome geeks.
Hello geeks.
Now Lets Extract Paragraphs from the given URL.
Code:
Python3
import requests
import pandas as pd
from bs4 import BeautifulSoup
def getdata(url):
r = requests.get(url)
return r.text
soup = BeautifulSoup(htmldata, 'html.parser')
data = ''
for data in soup.find_all("p"):
print(data.get_text())
|
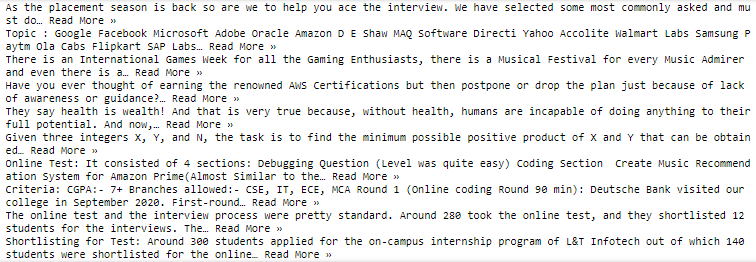
Output:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...