How to Make a Subdomain Scanner in Python?
Last Updated :
23 Jan, 2023
In this article, we are going to scan the subdomains using requests module in Python, which allows us to easily make HTTPS requests to get information from the websites. To install the requests module, write the following command in your command prompt.
pip install requests
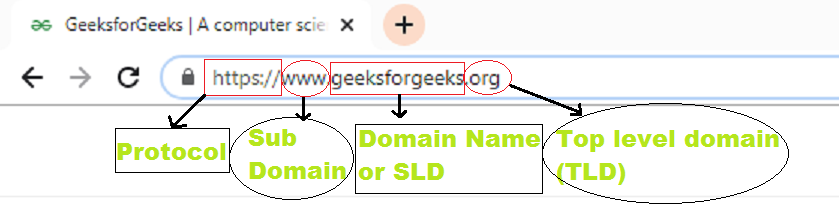
The URL (Uniform Resource Locator) consists mainly of four parts:
- Protocol
- Sub-domain
- Domain Name or Second level domain (SLD)
- Top-level domain (TLD)
The below figure demonstrating all four parts of the URL.
Subdomains are defined as the part of the domain that comes before the Domain name and Domain extension i.e, Top-level domain (TLD). Subdomains are used for organizing or dividing web content into distinct sections. Subdomains help us to separate our website into sections, subdomains are viewed as different websites.
Subdomain File Used:
mail
mail2
www
ns2
ns1
blog
localhost
m
ftp
mobile
ns3
smtp
search
api
dev
secure
webmail
admin
img
news
sms
marketing
test
video
www2
media
static
ads
mail2
beta
wap
blogs
download
dns1
www3
origin
shop
forum
chat
www1
image
new
tv
dns
services
music
images
pay
ddrint
conc
Approach:
- Firstly we have a list of subdomain names in the text file to scan those subdomains by putting in URL, you can get this list of subdomains from google.
- Now we have to create the URL by concatenating or using f string with protocol, subdomain, and domain name.
- We have to use for loop for putting subdomains in the URL one by one for scanning.
- To avoid the program to get crash when the subdomain is invalid with the domain name we have to use a try-catch block to skip that subdomain that was invalid and pass it with the help of catch block and scan the upcoming subdomain with the help of catch block, scanning should be done with the help of request module, for the specific URL get request should be sent to the server according to server response URL will be printed.
- As soon as subdomains are scanned and valid then URL is printed.
Steps Needed
- Import request module
- Create a function for scanning the subdomains and pass domain name and list of subdomains as a parameter.
- Run for loop for each subdomain present in the list, and concatenate subdomain with protocol and domain name in the URL sequence and stored it in the variable let named as “URL”.
- Now we use requests.get() function and in that pass, URL to retrieve the information from the given server by using given URL, if we are able to retrieve information from the server means that subdomain is valid with that domain name otherwise we will pass it for that we used to try and catch block in try block we will pass the request.get() function and after scanning, we will print that URL otherwise we will catch in the catch block and pass.
- Then create the main function, in the take user input of the domain name.
- Then open the list of the subdomains text files from the storage in read mode for scanning each subdomain.
- After opening the file in read mode we are using splitlines() function for storing the split strings in the variable let named as “sub_dom”.
- Now call the function which we had created for scanning the subdomain bypassing domain name and sub_dom.
Showing subdomain names present in the text file and creating a list of that subdomains.
Python
with open('subdomain_names.txt','r') as file:
name = file.read()
sub_dom = name.splitlines()
print(f"Number of subdomain names present in the file are: {len(sub_dom)}\n")
print("List of subdomain names present in the file\n")
print(sub_dom)
|
Output:

In the above code, we are opening the text file from the storage in which our subdomain names are present which we have to scan and also after opening the file from the storage in read mode we are making the list of content present in that file and printing number of subdomain names present in the file and printing the list of subdomain names.
The text file contains only 50 subdomains for demonstration you can take as many subdomain as you want to scan according to your need. So in the above output image list of subdomains is printed which we will scan in the upcoming example.
We will use this piece of code in scanning the subdomains.
Example 1: Subdomain scanner program using Python.
Python
import requests
def domain_scanner(domain_name,sub_domnames):
print('----URL after scanning subdomains----')
for subdomain in sub_domnames:
url = f"https://{subdomain}.{domain_name}"
try:
requests.get(url)
print(f'[+] {url}')
except requests.ConnectionError:
pass
if __name__ == '__main__':
dom_name = input("Enter the Domain Name:")
with open('subdomain_names1.txt','r') as file:
name = file.read()
sub_dom = name.splitlines()
domain_scanner(dom_name,sub_dom)
|
Output:

The scanning time will depend on the number of subdomains you are scanning, for the demonstration I have some names of subdomains in the text file, you can add as many as subdomains you want to scan.
Example 2: Subdomain scanner for Wikipedia using Python.
Python
import requests
def domain_scanner(domain_name,sub_domnames):
print('-----------Scanner Started-----------')
print('----URL after scanning subdomains----')
for subdomain in sub_domnames:
url = f"https://{subdomain}.{domain_name}"
try:
requests.get(url)
print(f'[+] {url}')
except requests.ConnectionError:
pass
print('\n')
print('----Scanning Finished----')
print('-----Scanner Stopped-----')
if __name__ == '__main__':
dom_name = input("Enter the Domain Name:")
print('\n')
with open('subdomain_names1.txt','r') as file:
name = file.read()
sub_dom = name.splitlines()
domain_scanner(dom_name,sub_dom)
|
Output:

Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...