How to handle missing values of categorical variables in Python?
Last Updated :
28 Sep, 2021
Machine Learning is the field of study that gives computers the capability to learn without being explicitly programmed. Often we come across datasets in which some values are missing from the columns. This causes problems when we apply a machine learning model to the dataset. This increases the chances of error when we are training the machine learning model.
The dataset we are using is:
Python3
import pandas as pd
import numpy as np
df = pd.read_csv("train.csv", header=None)
df.head
|
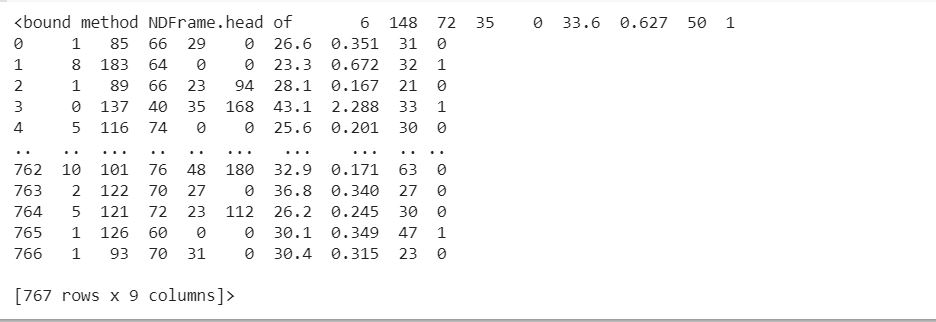
Counting the missing data:
Python3
cnt_missing = (df[[1, 2, 3, 4,
5, 6, 7, 8]] == 0).sum()
print(cnt_missing)
|

We see that for 1,2,3,4,5 column the data is missing. Now we will replace all 0 values with NaN.
Python
from numpy import nan
df[[1, 2, 3, 4, 5]] = df[[1, 2, 3, 4, 5]].replace(0, nan)
df.head(10)
|
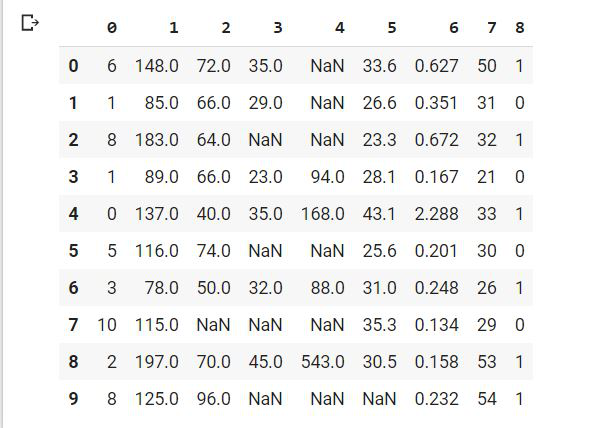
Handling missing data is important, so we will remove this problem by following approaches:
Approach #1
The first method is to simply remove the rows having the missing data.
Python3
print(df.shape)
df.dropna(inplace=True)
print(df.shape)
|

But in this, the problem that arises is that when we have small datasets and if we remove rows with missing data then the dataset becomes very small and the machine learning model will not give good results on a small dataset.
So to avoid this problem we have a second method. The next method is to input the missing values. We do this by either replacing the missing value with some random value or with the median/mean of the rest of the data.
Approach #2
We first impute missing values by the mean of the data.
Python3
df.fillna(df.mean(), inplace=True)
df.sample(10)
|
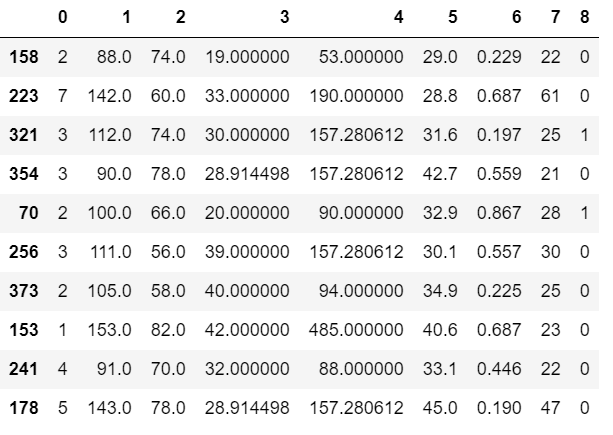
We can also do this by using SimpleImputer class. SimpleImputer is a scikit-learn class which is helpful in handling the missing data in the predictive model dataset. It replaces the NaN values with a specified placeholder.It is implemented by the use of the SimpleImputer() method which takes the following arguments:
SimpleImputer(missing_values, strategy, fill_value)
- missing_values : The missing_values placeholder which has to be imputed. By default is NaN.
- strategy : The data which will replace the NaN values from the dataset. The strategy argument can take the values – ‘mean'(default), ‘median’, ‘most_frequent’ and ‘constant’.
- fill_value : The constant value to be given to the NaN data using the constant strategy.
Python3
from numpy import isnan
from sklearn.impute import SimpleImputer
value = df.values
imputer = SimpleImputer(missing_values=nan,
strategy='mean')
transformed_values = imputer.fit_transform(value)
print("Missing:", isnan(transformed_values).sum())
|

Approach #3
We first impute missing values by the median of the data. Median is the middle value of a set of data. To determine the median value in a sequence of numbers, the numbers must first be arranged in ascending order.
Python3
df.fillna(df.median(), inplace=True)
df.head(10)
|
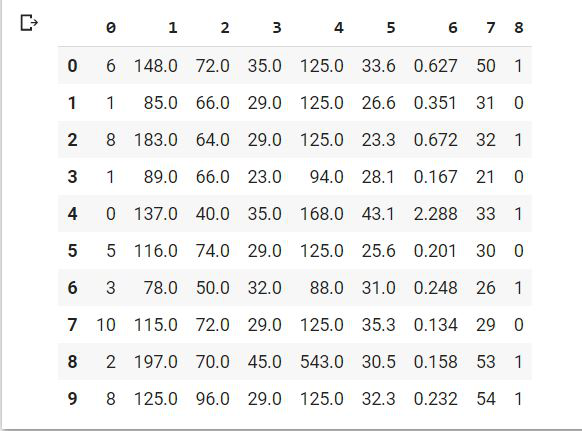
We can also do this by using SimpleImputer class.
Python3
from numpy import isnan
from sklearn.impute import SimpleImputer
value = df.values
imputer = SimpleImputer(missing_values=nan,
strategy='median')
transformed_values = imputer.fit_transform(value)
print("Missing:", isnan(transformed_values).sum())
|
Approach #4
We first impute missing values by the mode of the data. The mode is the value that occurs most frequently in a set of observations. For example, {6, 3, 9, 6, 6, 5, 9, 3} the Mode is 6, as it occurs most often.
Python3
df.fillna(df.mode(), inplace=True)
df.sample(10)
|
We can also do this by using SimpleImputer class.
Python3
from numpy import isnan
from sklearn.impute import SimpleImputer
value = df.values
imputer = SimpleImputer(missing_values=nan,
strategy='most_frequent')
transformed_values = imputer.fit_transform(value)
print("Missing:", isnan(transformed_values).sum())
|
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...