How to Find Duplicate Values in a SQL Table using Python?
Last Updated :
13 Feb, 2023
MySQL server is an open-source relational database management system that is a major support for web-based applications. Databases and related tables are the main component of many websites and applications as the data is stored and exchanged over the web. In order to access MySQL databases from a web server, we use various modules in Python such as PyMySQL, mysql.connector, etc.
In this article, we are going to find duplicate values in a specific MySQL table in a Database. First, we are going to connect to a database having a MySQL table. The SQL query that is going to be used is:
SELECT * FROM table-name
GROUP BY col_1, col_2,..., col_n
HAVING COUNT(*) > 1;
If the table has a primary key then the below query can also be used:
SELECT * FROM table-name
GROUP BY primary-key
HAVING COUNT(*) > 1;
The above queries will generate only duplicate rows in a table, and then these rows will be displayed as output.
Below are some programs which depict how to find duplicate values in a specific MySQL table in a Database:
Example 1
Below is the table Documentary in database geek which is going to be accessed by a Python script:
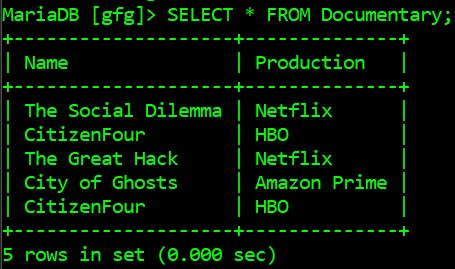
Below is the program to get the duplicate rows in the MySQL table:
Python3
import mysql.connector
db = mysql.connector.connect(host='localhost',
database='gfg',
user='root',
password='')
cursor = db.cursor()
cursor.execute("SELECT * FROM Documentary \
GROUP BY Name, Production \
HAVING COUNT(*) > 1;")
print('Duplicate Rows:')
for row in cursor.fetchall(): print(row)
db.close()
|
Output:
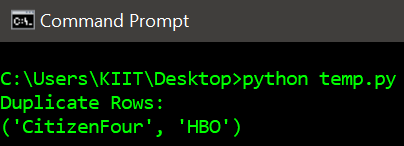
Example 2:
Here is another example to find the duplicate rows from a table in a given database, below is the table scheme and rows:
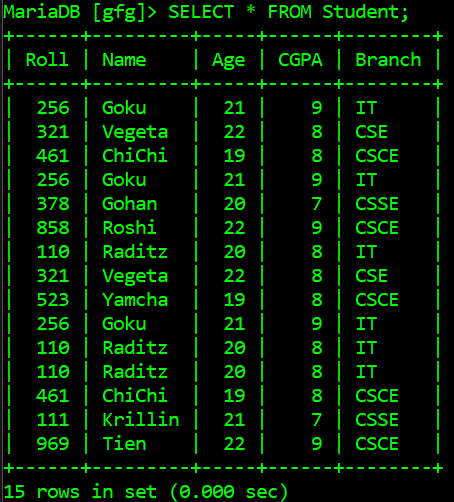
As we can see the Roll attribute is the primary key of the Student table, hence it only can be used with the GROUP BY statement in the query to generate the duplicate rows, below is the python script to get row count from the table Student:
Python3
import mysql.connector
db = mysql.connector.connect(host='localhost',
database='gfg',
user='root',
password='')
cursor = db.cursor()
cursor.execute("SELECT * FROM Student \
GROUP BY Roll \
HAVING COUNT(*) > 1;")
print('Duplicate Rows:')
for row in cursor.fetchall(): print(row)
db.close()
|
Output:
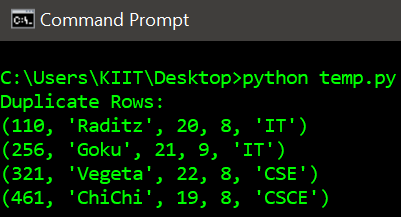
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...