How to Find and Remove Duplicate Files on Linux?
Last Updated :
02 Jan, 2023
Most of us have a habit of downloading many types of stuff (songs, files, etc) from the internet and that is why we may often find we have downloaded the same mp3 files, PDF files, and other extensions. Your disk spaces are unnecessarily wasted by Duplicate files and if you want the same files on a different location you can always set up a soft link or hard link that doesn’t eat the space unnecessarily and store the data in only one location on your disk. This will end up eating your system space unnecessarily and manually locating this duplicate file is quite a tough job. So there are some good tools in Linux for locating duplicate files and removing them to free up your system space by scanning your system, no matter you’re using Linux on your desktop or on a server.
Note: Whenever you’re trying a new tool make sure to first try it on a test directory where deleting files will not be a problem
Method 1: Using FSlint.
FSlint is a tool that helps us to search and remove unnecessary duplicate files, empty directories, temp files, or files with incorrect names completely and free up the disk space on your Linux system. FSlint provides a convenient GUI by default, but it also has CLI modes for various functions which are quite convenient for new users of Linux.
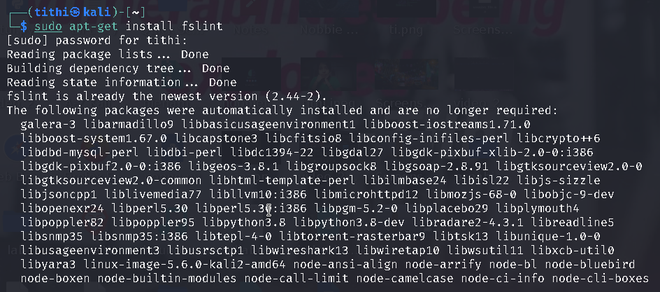
Install fslint in Linux using the following commands:
sudo apt-get install fslint

Fslint Interface
When the FSlint interface will be open you will find that by default, FSlint interface is opened with the Duplicates panel being selected and your home directory is set as the default search path, You will find other several numbers options to choose from like: installed packages, bad names, name clashes, temp files, empty directories, Bad IDs, etc.
Steps to use:
Step 1: First choose the task that you want to perform from the left panel like I am choosing the Duplicates panel option, you can choose the other panel too.
Step 2: Choose the Search Path where you want to perform the task
Step 3: Click on the Find option to locate the files.

Some directories may not be displayed/deleted due to permission issues
Once you get duplicate files (according to the option you choose), you can select and delete them. There is an Advanced search parameter where you can rule can be defined to exclude certain file types or directories which you don’t want to include in the search.

Advanced search parameters
Method 2: Using Fdupe.
Fdupe is another duplicate file removal tool residing within specified directories like fslint but unlike fslint, Fdupe is a command-line interface tool.It is a free and open-source tool written in C. Fdupe uses several modes of searching, they are:
- By size
- Comparing full or partial MD5 signatures and by comparing each byte.
- Byte-by-byte comparison
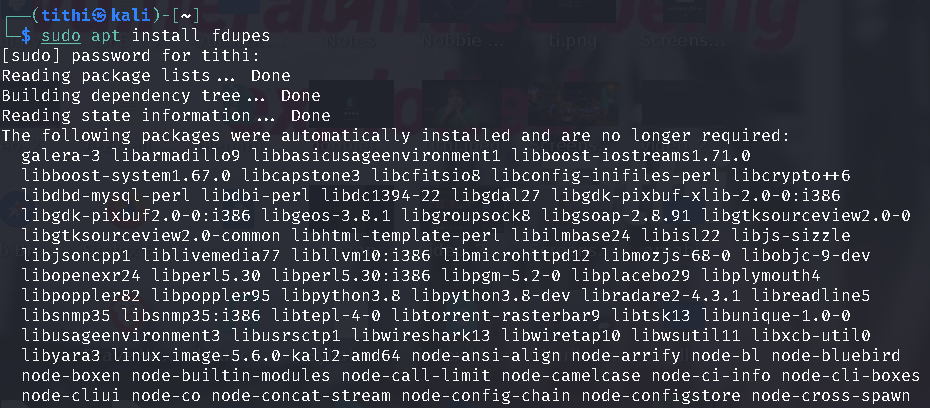
Install fdupe in Linux using the following commands:
sudo apt install fdupes
After installation simply run the fdupes command followed by the path to a directory that you want to scan.

Duplicate files being displayed
This tool will not automatically delete anything, it will just show you a list of all the duplicate files. You can then delete the duplicate files according to your choice.
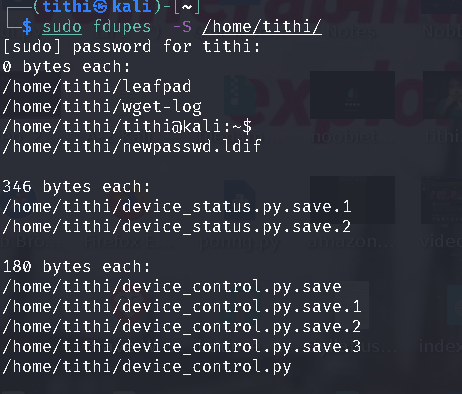
The size of the duplicate files is calculated by -S option:
At last, if you want to delete all duplicates you can use the -d option like the given screenshot:

fdupes -d /path/to/directory
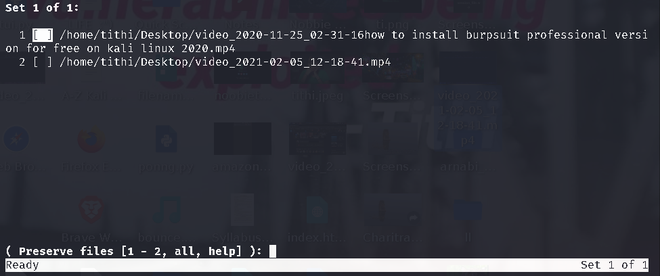
In the above screenshots, we can see the -d command showing all the duplicate files within the folder and giving you the option to select the file which you want to keep(preserve files option), by giving you the option to either delete files one by one or select a range to delete it or all at once. Even If you want to delete all files without asking and preserve the first one, you can use the -N option.
For more option see the help option of fdupes by typing fdupes -h:

fdupes help
Share your thoughts in the comments
Please Login to comment...