How to drop rows in Pandas DataFrame by index labels?
Last Updated :
01 Dec, 2023
Pandas provide data analysts a way to delete and filter dataframe using the .drop() method. Rows can be removed using index labels or column names using this method. In this article, we will see how to drop rows in Pandas Dataframe by index labels.
Pandas Drop Rows by Index
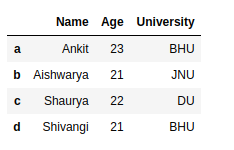
Creating a Simple Pandas Dataframe.
Python3
# import pandas library
import pandas as pd
# dictionary with list object in values
details = {
'Name': ['Ankit', 'Aishwarya', 'Shaurya', 'Shivangi'],
'Age': [23, 21, 22, 21],
'University': ['BHU', 'JNU', 'DU', 'BHU'],
}
# creating a Dataframe object
df = pd.DataFrame(details, columns=['Name', 'Age', 'University'],
index=['a', 'b', 'c', 'd'])
df
Output
Drop Rows by Index in Pandas DataFrame Examples
Delete a Single Row in DataFrame by Row Index Label
To remove a row from a DataFrame by its index label, the drop() function in pandas can be utilized. By passing the specific index label of the row we want to eliminate, this function removes that particular row from the DataFrame. An illustration of this process is demonstrated in the following example.
Python3
# import pandas library
import pandas as pd
# dictionary with list object in values
details = {
'Name': ['Ankit', 'Aishwarya', 'Shaurya', 'Shivangi'],
'Age': [23, 21, 22, 21],
'University': ['BHU', 'JNU', 'DU', 'BHU'],
}
# creating a Dataframe object
df = pd.DataFrame(details, columns=['Name', 'Age', 'University'],
index=['a', 'b', 'c', 'd'])
# return a new dataframe by dropping a
# row 'c' from dataframe
update_df = df.drop('c')
update_df
Output
Name Age University
a Ankit 23 BHU
b Aishwarya 21 JNU
d Shivangi 21 BHU
Delete Multiple Rows in DataFrame by Index Labels
The drop() function in pandas allows for the removal of multiple rows by providing a list of index labels. By passing a list containing the desired rows to be dropped, the function eliminates those specified rows from the DataFrame. The result is a new DataFrame that retains the remaining rows after the removal process. This versatile functionality enhances the flexibility of data manipulation in pandas.
Python3
# import pandas library
import pandas as pd
# dictionary with list object in values
details = {
'Name': ['Ankit', 'Aishwarya', 'Shaurya', 'Shivangi'],
'Age': [23, 21, 22, 21],
'University': ['BHU', 'JNU', 'DU', 'BHU'],
}
# creating a Dataframe object
df = pd.DataFrame(details, columns=['Name', 'Age', 'University'],
index=['a', 'b', 'c', 'd'])
# return a new dataframe by dropping a row
# 'b' & 'c' from dataframe
update_df = df.drop(['b', 'c'])
update_df
Output
Name Age University
a Ankit 23 BHU
d Shivangi 21 BHU
Delete a Multiple Rows by Index Position in DataFrame
In this example, we are using pandas library to construct a DataFrame ‘df’ from a dictionary named ‘details,’ organizing the data with specific columns and row indices. Subsequently, a new DataFrame ‘update_df’ is created by dropping rows with index positions 1 and 2 (representing ‘b’ and ‘c’) from the original DataFrame ‘df’. As a result, ‘update_df’ contains data solely from rows ‘a’ and ‘d,’ reflecting the exclusion of the specified rows based on their respective index positions.
Python3
# import pandas library
import pandas as pd
# dictionary with list object in values
details = {
'Name': ['Ankit', 'Aishwarya', 'Shaurya', 'Shivangi'],
'Age': [23, 21, 22, 21],
'University': ['BHU', 'JNU', 'DU', 'BHU'],
}
# creating a Dataframe object
df = pd.DataFrame(details, columns=['Name', 'Age', 'University'],
index=['a', 'b', 'c', 'd'])
# return a new dataframe by dropping a row
# 'b' & 'c' from dataframe using their
# respective index position
update_df = df.drop([df.index[1], df.index[2]])
update_df
Python3
# import pandas library
import pandas as pd
# dictionary with list object in values
details = {
'Name': ['Ankit', 'Aishwarya', 'Shaurya', 'Shivangi'],
'Age': [23, 21, 22, 21],
'University': ['BHU', 'JNU', 'DU', 'BHU'],
}
# creating a Dataframe object
df = pd.DataFrame(details, columns=['Name', 'Age', 'University'],
index=['a', 'b', 'c', 'd'])
# dropping a row 'c' & 'd' from actual dataframe
df.drop(['c', 'd'], inplace=True)
df