How to add header row to a Pandas Dataframe?
Last Updated :
07 Dec, 2023
A header necessarily stores the names or headings for each of the columns. It helps the user to identify the role of the respective column in the data frame. The top row containing column names is called the header row of the data frame. There are two approaches to add header row to a Pandas Dataframe in case the original dataframe doesn’t have a header.
Add Header Row to a Pandas Dataframe
There are various ways to Add header row to a Pandas Dataframe, we explain some generally used methods for Pandas set Header Row to a Pandas Dataframe
Pandas Add Header Row to Dataframe using Read_csv and Print
While reading the data and storing it in a data frame, or creating a fresh data frame, column names can be specified by using the names attribute of the read_csv() method in Python. Names attribute contains an array of names for each of the columns of the data frame in order. The length of the array is equivalent to the length of this frame structure.
Python3
import pandas as pd
data_frame = pd.read_csv("test.txt", sep='\t',
names=['Name', 'Age', 'Profession'])
print("Data frame")
print(data_frame)
print("Row header")
print(list(data_frame.columns))
|
Output:
Data frame
Name Age Profession
0 Mallika 23 Student
1 Yash 25 Tutor
2 Abc 14 Clerk
Row header
['Name', 'Age', 'Profession']
We can also specify the header=none as an attribute of the read_csv() method and later on give names to the columns explicitly when desired.
Python3
import pandas as pd
data_frame = pd.read_csv("test.txt")
print("Original Data frame")
print(data_frame)
data_frame_new = pd.read_csv("test.txt", names=['A', 'B', 'C'])
print("New Data frame")
print(data_frame_new)
print("Row header")
print(list(data_frame_new.columns))
|
Output:
Data frame
Name Age Profession
0 Mallika 23 Student
1 Yash 25 Tutor
2 Abc 14 Clerk
Row header
['Name', 'Age', 'Profession']
Originally, the rows are numbered by index numbers beginning from 0, in case the CSV file does not have any row header.
Creating a data frame and creating row header in Python itself
Adding Headers to a Dataframe in Pandas using Pandas Dataframe itself by creating a data frame of specific number of rows and columns by first creating a multi -dimensional array and then converting it into a data frame by the pandas.DataFrame() method. The columns argument is used to specify the row header or the column names. It contains an array of column values with its length equal to the number of columns in the data frame.
Python3
import pandas as pd
data = [['Mallika', 23, 'Student'], [
'Yash', 25, 'Tutor'], ['Abc', 14, 'Clerk']]
data_frame = pd.DataFrame(data, columns=['Name', 'Age', 'Profession'])
print("Data frame")
print(data_frame)
print("Row header")
print(list(data_frame.columns))
|
Output:
Data frame
Name Age Profession
0 Mallika 23 Student
1 Yash 25 Tutor
2 Abc 14 Clerk
Row header
['Name', 'Age', 'Profession']
Creating a data frame from CSV file and using set_axis() Method
We create a data frame of specific number of rows and columns by first creating a multi -dimensional array and then converting it into a data frame by the pandas.DataFrame() method. The set_axis() methods argument is used to specify the row header or the column names. It contains an array of column values with its length equal to the number of columns in the data frame.
Python3
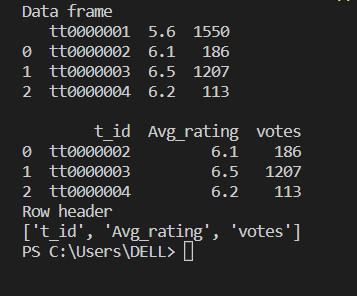
import pandas as pd
data_frame=pd.read_csv("C:\\Users\\DELL\\Downloads\\data.tsv",
sep='\t')
print("Data frame")
print(data_frame)
data_frame.set_axis(["t_id", "Avg_rating", "votes"],
axis=1,inplace=True)
print()
print(data_frame)
print("Row header")
print(list(data_frame.columns))
|
Output :
Output
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...