Hive – Drop Table
Last Updated :
04 Nov, 2020
Apache hive is a data warehousing tool that we use to manage our structure data on Hadoop. The tables in the hive are used for storing data in tabular format(structured). Hive is very much capable such that it can query petabytes of records stored inside the hive table.
DROP TABLE command in the hive is used to drop a table inside the hive. Hive will remove all of its data and metadata from the hive meta-store. The hive DROP TABLE statement comes with a PURGE option. In case if the PURGE option is mentioned the data will be completely lost and cannot be recovered later but if not mentioned then data will move to .Trash/current directory.
Syntax:
DROP TABLE [IF EXISTS] table_name [PURGE];
Example:
To perform the below operation make sure your hive is running. Below are the steps to launch a hive on your local system.
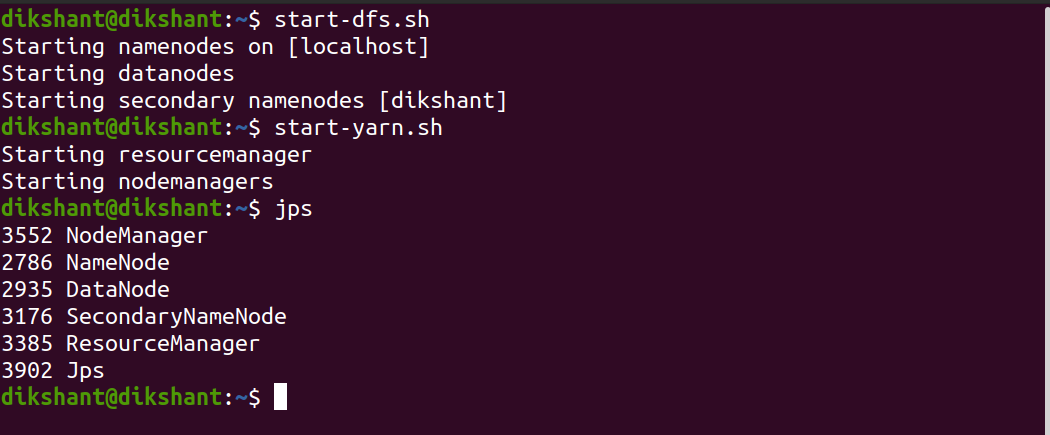
Step 1: Start all your Hadoop Daemon
start-dfs.sh # this will start namenode, datanode and secondary namenode
start-yarn.sh # this will start node manager and resource manager
jps # To check running daemons
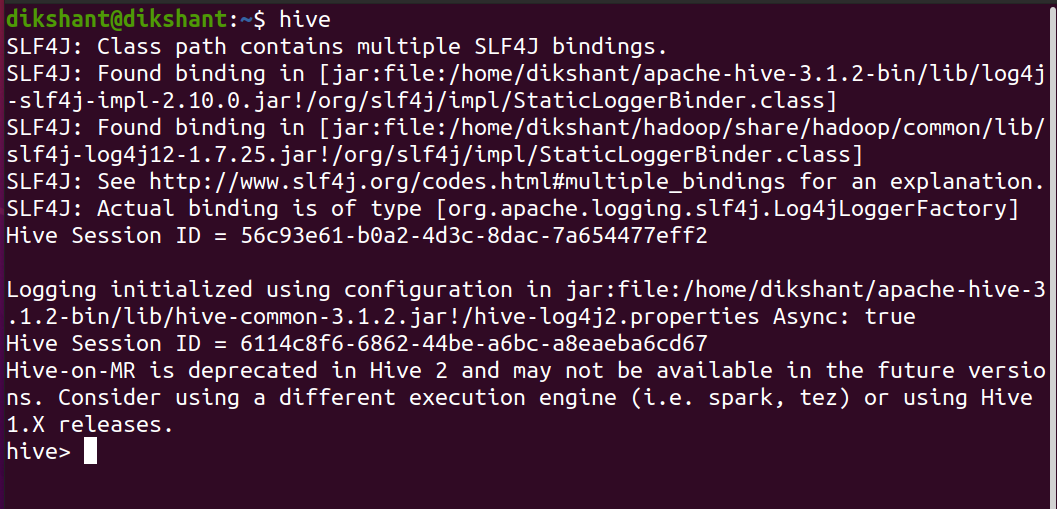
Step 2: Launch Hive
hive
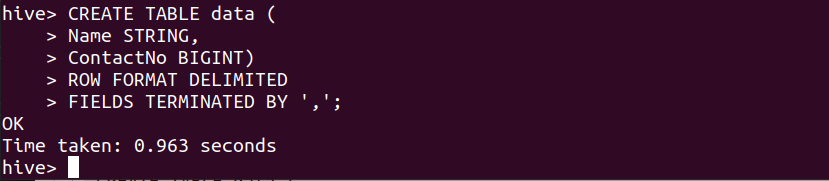
Let’s create a table in the hive first with the below command so that we can DROP it with the DROP TABLE statement. In our example, we are not specifying any database name so hive will use its default database.
Command:
CREATE TABLE data (
Name STRING,
ContactNo BIGINT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
We have successfully created a data table in the default database of the hive. Below is the command to check
Syntax:
SHOW TABLES IN <database-name>;
Command:
show tables in default;

DROP TABLE in Hive
With the help of the below command, all the content of the data table will be removed permanently because I have used the PURGE option with the DROP TABLE command.
Command:
DROP TABLE IF EXISTS data PURGE;

The table is successfully dropped.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...