Hierarchical clustering using Weka
Last Updated :
30 May, 2021
In this article, we will see how to utilize the Weka Explorer to perform hierarchical analysis. The sample data set for this example is based on iris data in ARFF format. The data has been appropriately preprocessed, as this article expects. This dataset has 150 iris occurrences.
Clustering: Clustering is the method of dividing a set of abstract objects into groups. Points to Keep in Mind A set of data objects can be viewed as a single entity. When performing cluster analysis, we divide the data set into groups based on data similarity, then assign labels to the groups.
Hierarchical clustering: Hierarchical clustering, also known as Hierarchical cluster analysis or HCA, is an unsupervised clustering approach that includes forming groups with a top-to-bottom order.
For example, on our hard drive, all files and folders are organized in a hierarchy.
The program divides objects into clusters based on their similarity. The endpoint is a collection of clusters or groups, each of which is distinct from the others, yet the items inside each cluster are broadly similar.
Steps to be followed:
Step 1: Open the Weka explorer in the preprocessing interface and import the appropriate dataset; I’m using the iris.arff dataset.
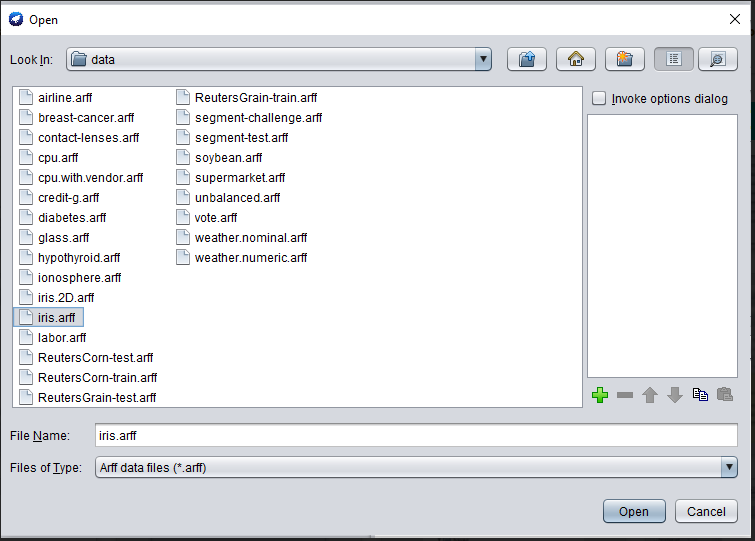
Step 2: To perform clustering, go to the explorer’s ‘cluster’ tab and select the select button. As a result of this step, a dropdown list of available clustering algorithms displays; pick the Hierarchical algorithm.
Step 3: Then press the text button to the right of the pick icon to bring up the popup window seen in the screenshots. In this window, we input three for the number of clusters and leave the seed value alone. The seed value is used to generate a random number that is used to allocate cluster instances to each other internally.

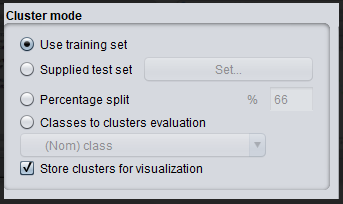
Step 4: One of the options has been selected. Before we execute the clustering method, we need to make sure they’re in the ‘cluster mode’ panel. The option to employ a training set is chosen, after which the ‘start’ button is hit. The process and the resulting window are depicted in the screenshots below.
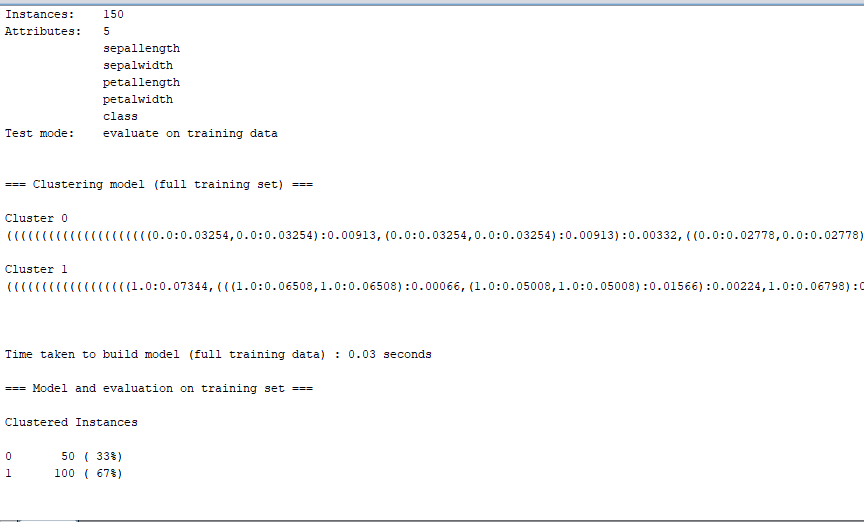
Step 5: The resulting window displays the centroid of each cluster, as well as data on the number and proportion of instances assigned to each cluster. A mean vector is used to represent each cluster centroid. A cluster can be described using this cluster.
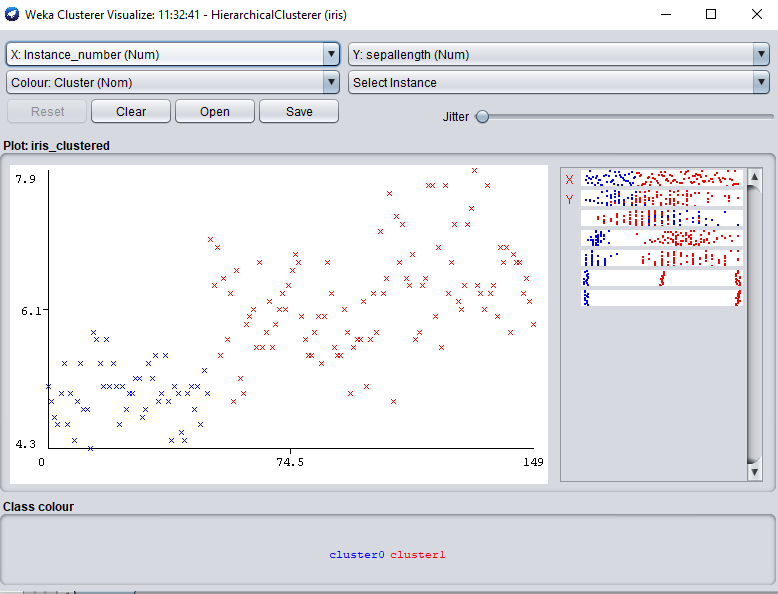
Step 6: Visualizing the qualities of each cluster is another approach to grasp them. Right-click the result set on the result to do so. To visualize cluster assignments are selected from the list column.
Share your thoughts in the comments
Please Login to comment...