Hash Map in Python
Last Updated :
20 Aug, 2023
Hash maps are indexed data structures. A hash map makes use of a hash function to compute an index with a key into an array of buckets or slots. Its value is mapped to the bucket with the corresponding index. The key is unique and immutable. Think of a hash map as a cabinet having drawers with labels for the things stored in them. For example, storing user information- consider email as the key, and we can map values corresponding to that user such as the first name, last name etc to a bucket.
Hash function is the core of implementing a hash map. It takes in the key and translates it to the index of a bucket in the bucket list. Ideal hashing should produce a different index for each key. However, collisions can occur. When hashing gives an existing index, we can simply use a bucket for multiple values by appending a list or by rehashing.
In Python, dictionaries are examples of hash maps. We’ll see the implementation of hash map from scratch in order to learn how to build and customize such data structures for optimizing search.
The hash map design will include the following functions:
- set_val(key, value): Inserts a key-value pair into the hash map. If the value already exists in the hash map, update the value.
- get_val(key): Returns the value to which the specified key is mapped, or “No record found” if this map contains no mapping for the key.
- delete_val(key): Removes the mapping for the specific key if the hash map contains the mapping for the key.
Below is the implementation.
Python3
class HashTable:
def __init__(self, size):
self.size = size
self.hash_table = self.create_buckets()
def create_buckets(self):
return [[] for _ in range(self.size)]
def set_val(self, key, val):
hashed_key = hash(key) % self.size
bucket = self.hash_table[hashed_key]
found_key = False
for index, record in enumerate(bucket):
record_key, record_val = record
if record_key == key:
found_key = True
break
if found_key:
bucket[index] = (key, val)
else:
bucket.append((key, val))
def get_val(self, key):
hashed_key = hash(key) % self.size
bucket = self.hash_table[hashed_key]
found_key = False
for index, record in enumerate(bucket):
record_key, record_val = record
if record_key == key:
found_key = True
break
if found_key:
return record_val
else:
return "No record found"
def delete_val(self, key):
hashed_key = hash(key) % self.size
bucket = self.hash_table[hashed_key]
found_key = False
for index, record in enumerate(bucket):
record_key, record_val = record
if record_key == key:
found_key = True
break
if found_key:
bucket.pop(index)
return
def __str__(self):
return "".join(str(item) for item in self.hash_table)
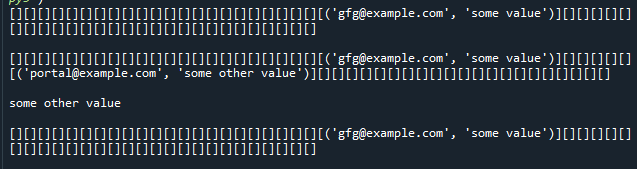
hash_table = HashTable(50)
hash_table.set_val('gfg@example.com', 'some value')
print(hash_table)
print()
hash_table.set_val('portal@example.com', 'some other value')
print(hash_table)
print()
print(hash_table.get_val('portal@example.com'))
print()
hash_table.delete_val('portal@example.com')
print(hash_table)
|
Output:
Time Complexity:
Memory index access takes constant time and hashing takes constant time. Hence, the search complexity of a hash map is also constant time, that is, O(1).
Advantages of HashMaps
● Fast random memory access through hash functions
● Can use negative and non-integral values to access the values.
● Keys can be stored in sorted order hence can iterate over the maps easily.
Disadvantages of HashMaps
● Collisions can cause large penalties and can blow up the time complexity to linear.
● When the number of keys is large, a single hash function often causes collisions.
Applications of HashMaps
● These have applications in implementations of Cache where memory locations are mapped to small sets.
● They are used to index tuples in Database management systems.
● They are also used in algorithms like the Rabin Karp pattern matching
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...