Hadoop – Introduction
Last Updated :
29 Jul, 2021
The definition of a powerful person has changed in this world. A powerful is one who has access to the data. This is because data is increasing at a tremendous rate. Suppose we are living in 100% data world. Then 90% of the data is produced in the last 2 to 4 years. This is because now when a child is born, before her mother, she first faces the flash of the camera. All these pictures and videos are nothing but data. Similarly, there is data of emails, various smartphone applications, statistical data, etc. All this data has the enormous power to affect various incidents and trends. This data is not only used by companies to affect their consumers but also by politicians to affect elections. This huge data is referred to as Big Data. In such a world, where data is being produced at such an exponential rate, it needs to maintained, analyzed, and tackled. This is where Hadoop creeps in.
Hadoop is a framework of the open source set of tools distributed under Apache License. It is used to manage data, store data, and process data for various big data applications running under clustered systems. In the previous years, Big Data was defined by the “3Vs” but now there are “5Vs” of Big Data which are also termed as the characteristics of Big Data.
- Volume: With increasing dependence on technology, data is producing at a large volume. Common examples are data being produced by various social networking sites, sensors, scanners, airlines and other organizations.
- Velocity: Huge amount of data is generated per second. It is estimated that by the end of 2020, every individual will produce 3mb data per second. This large volume of data is being generated with a great velocity.
- Variety: The data being produced by different means is of three types:
- Structured Data: It is the relational data which is stored in the form of rows and columns.
- Unstructured Data: Texts, pictures, videos etc. are the examples of unstructured data which can’t be stored in the form of rows and columns.
- Semi Structured Data: Log files are the examples of this type of data.
- Veracity: The term Veracity is coined for the inconsistent or incomplete data which results in the generation of doubtful or uncertain Information. Often data inconsistency arises because of the volume or amount of data e.g. data in bulk could create confusion whereas less amount of data could convey half or incomplete Information.
- Value: After having the 4 V’s into account there comes one more V which stands for Value!. Bulk of Data having no Value is of no good to the company, unless you turn it into something useful. Data in itself is of no use or importance but it needs to be converted into something valuable to extract Information. Hence, you can state that Value! is the most important V of all the 5V’s
Evolution of Hadoop: Hadoop was designed by Doug Cutting and Michael Cafarella in 2005. The design of Hadoop is inspired by Google. Hadoop stores the huge amount of data through a system called Hadoop Distributed File System (HDFS) and processes this data with the technology of Map Reduce. The designs of HDFS and Map Reduce are inspired by the Google File System (GFS) and Map Reduce. In the year 2000 Google suddenly overtook all existing search engines and became the most popular and profitable search engine. The success of Google was attributed to its unique Google File System and Map Reduce. No one except Google knew about this, till that time. So, in the year 2003 Google released some papers on GFS. But it was not enough to understand the overall working of Google. So in 2004, Google again released the remaining papers. The two enthusiasts Doug Cutting and Michael Cafarella studied those papers and designed what is called, Hadoop in the year 2005. Doug’s son had a toy elephant whose name was Hadoop and thus Doug and Michael gave their new creation, the name “Hadoop” and hence the symbol “toy elephant.” This is how Hadoop evolved. Thus the designs of HDFS and Map Reduced though created by Doug Cutting and Michael Cafarella, but are originally inspired by Google. For more details about the evolution of Hadoop, you can refer to Hadoop | History or Evolution.
Traditional Approach: Suppose we want to process a data. In the traditional approach, we used to store data on local machines. This data was then processed. Now as data started increasing, the local machines or computers were not capable enough to store this huge data set. So, data was then started to be stored on remote servers. Now suppose we need to process that data. So, in the traditional approach, this data has to be fetched from the servers and then processed upon. Suppose this data is of 500 GB. Now, practically it is very complex and expensive to fetch this data. This approach is also called Enterprise Approach.
In the new Hadoop Approach, instead of fetching the data on local machines we send the query to the data. Obviously, the query to process the data will not be as huge as the data itself. Moreover, at the server, the query is divided into several parts. All these parts process the data simultaneously. This is called parallel execution and is possible because of Map Reduce. So, now not only there is no need to fetch the data, but also the processing takes lesser time. The result of the query is then sent to the user. Thus the Hadoop makes data storage, processing and analyzing way easier than its traditional approach.
Components of Hadoop: Hadoop has three components:
- HDFS: Hadoop Distributed File System is a dedicated file system to store big data with a cluster of commodity hardware or cheaper hardware with streaming access pattern. It enables data to be stored at multiple nodes in the cluster which ensures data security and fault tolerance.
- Map Reduce : Data once stored in the HDFS also needs to be processed upon. Now suppose a query is sent to process a data set in the HDFS. Now, Hadoop identifies where this data is stored, this is called Mapping. Now the query is broken into multiple parts and the results of all these multiple parts are combined and the overall result is sent back to the user. This is called reduce process. Thus while HDFS is used to store the data, Map Reduce is used to process the data.
- YARN : YARN stands for Yet Another Resource Negotiator. It is a dedicated operating system for Hadoop which manages the resources of the cluster and also functions as a framework for job scheduling in Hadoop. The various types of scheduling are First Come First Serve, Fair Share Scheduler and Capacity Scheduler etc. The First Come First Serve scheduling is set by default in YARN.
How the components of Hadoop make it as a solution for Big Data?
- Hadoop Distributed File System: In our local PC, by default the block size in Hard Disk is 4KB. When we install Hadoop, the HDFS by default changes the block size to 64 MB. Since it is used to store huge data. We can also change the block size to 128 MB. Now HDFS works with Data Node and Name Node. While Name Node is a master service and it keeps the metadata as for on which commodity hardware, the data is residing, the Data Node stores the actual data. Now, since the block size is of 64 MB thus the storage required to store metadata is reduced thus making HDFS better. Also, Hadoop stores three copies of every dataset at three different locations. This ensures that the Hadoop is not prone to single point of failure.
- Map Reduce: In the simplest manner, it can be understood that MapReduce breaks a query into multiple parts and now each part process the data coherently. This parallel execution helps to execute a query faster and makes Hadoop a suitable and optimal choice to deal with Big Data.
- YARN: As we know that Yet Another Resource Negotiator works like an operating system to Hadoop and as operating systems are resource managers so YARN manages the resources of Hadoop so that Hadoop serves big data in a better way.
Hadoop Versions: Till now there are three versions of Hadoop as follows.
- Hadoop 1: This is the first and most basic version of Hadoop. It includes Hadoop Common, Hadoop Distributed File System (HDFS), and Map Reduce.
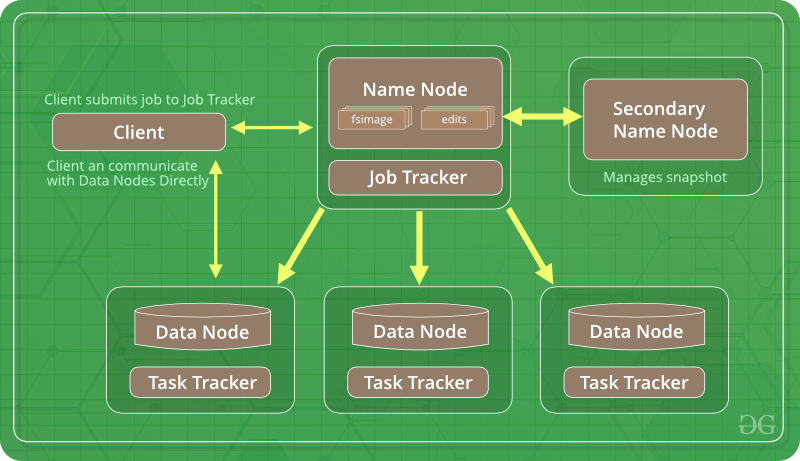
- Hadoop 2: The only difference between Hadoop 1 and Hadoop 2 is that Hadoop 2 additionally contains YARN (Yet Another Resource Negotiator). YARN helps in resource management and task scheduling through its two daemons namely job tracking and progress monitoring.
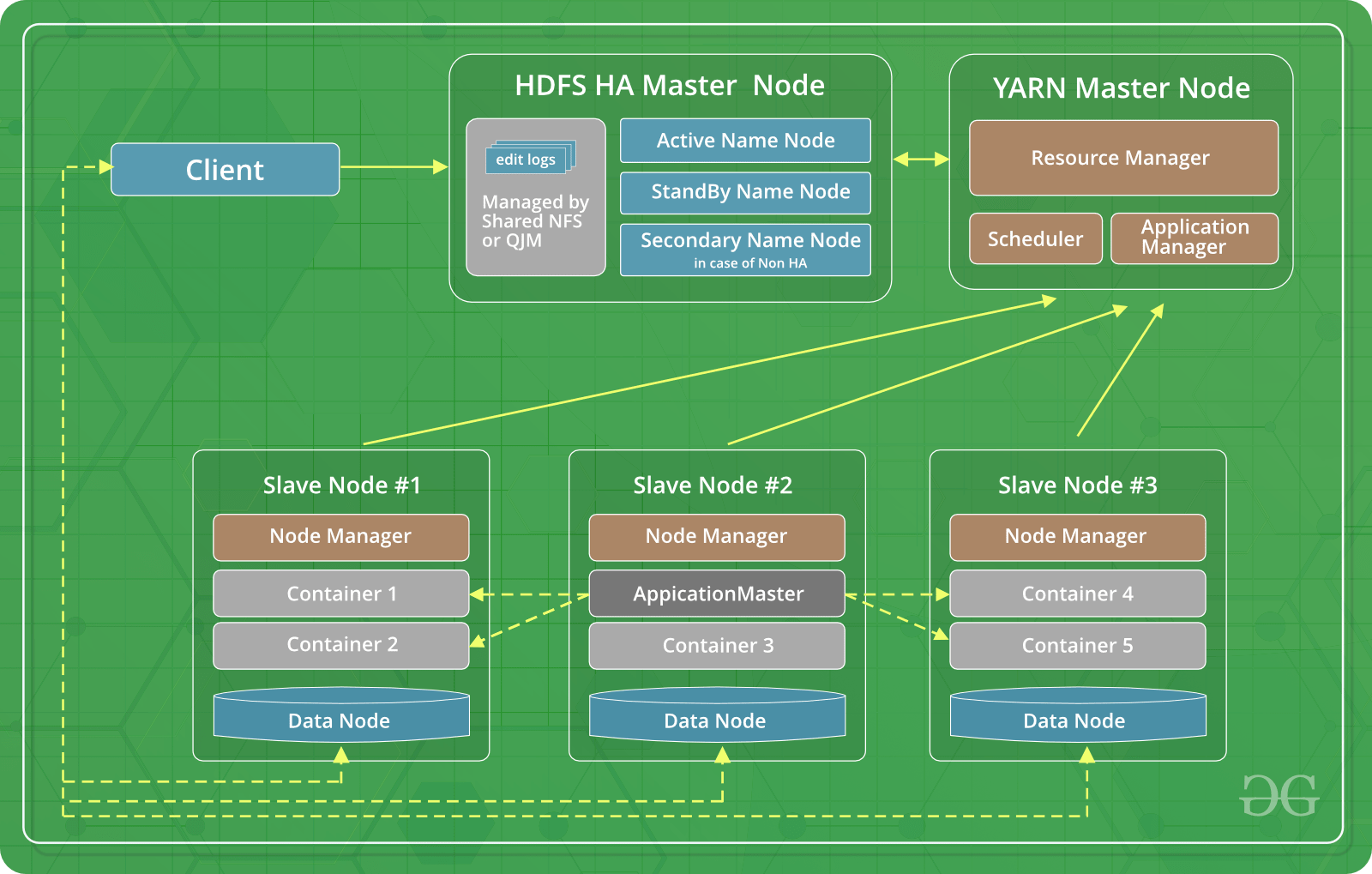
- Hadoop 3: This is the recent version of Hadoop. Along with the merits of the first two versions, Hadoop 3 has one most important merit. It has resolved the issue of single point failure by having multiple name nodes. Various other advantages like erasure coding, use of GPU hardware and Dockers makes it superior to the earlier versions of Hadoop.
- Economically Feasible: It is cheaper to store data and process it than it was in the traditional approach. Since the actual machines used to store data are only commodity hardware.
- Easy to Use: The projects or set of tools provided by Apache Hadoop are easy to work upon in order to analyze complex data sets.
- Open Source: Since Hadoop is distributed as an open source software under Apache License, so one does not need to pay for it, just download it and use it.
- Fault Tolerance: Since Hadoop stores three copies of data, so even if one copy is lost because of any commodity hardware failure, the data is safe. Moreover, as Hadoop version 3 has multiple name nodes, so even the single point of failure of Hadoop has also been removed.
- Scalability: Hadoop is highly scalable in nature. If one needs to scale up or scale down the cluster, one only needs to change the number of commodity hardware in the cluster.
- Distributed Processing: HDFS and Map Reduce ensures distributed storage and processing of the data.
- Locality of Data: This is one of the most alluring and promising features of Hadoop. In Hadoop, to process a query over a data set, instead of bringing the data to the local computer we send the query to the server and fetch the final result from there. This is called data locality.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...