GrowNet was proposed in 2020 by students from Purdue, UCLA, and Virginia Tech in collaboration with engineers from Amazon and LinkedIn California. They proposed a new gradient boosting algorithm where they used a shallow neural network as the weak learners, a general loss function for training the gradient boosting models under classification, regression, and learning to rank, and a fully corrective step to deal with pitfalls of gradient training and provide stability to it.
Before going on to the architectural details of the GrowNet, it is a prerequisite to have a quick revision at the Gradient Boosting.
Gradient Boosting
Gradient Boosting is a popular boosting algorithm. In gradient boosting, each predictor corrects its predecessor’s error. In contrast to Adaboost, the weights of the training instances are not tweaked, instead, each predictor is trained using the residual errors of predecessor as labels.
There is a technique called the Gradient Boosted
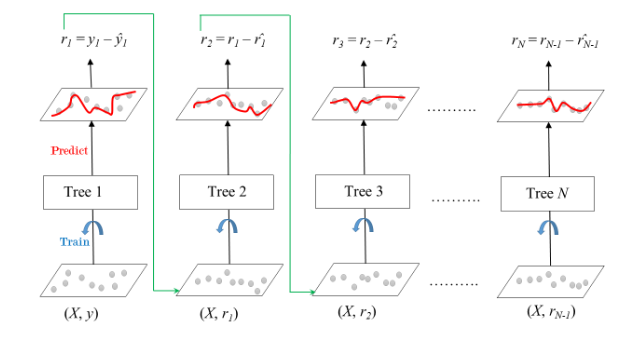
Trees whose base learner is CART (Classification and Regression Trees). The diagram explains how gradient boosted trees are trained for regression problems.
The ensemble consists of N trees. Tree1 is trained using the feature matrix X and the labels y. The predictions labelled  are used to determine the training set residual errors
are used to determine the training set residual errors  . Tree2 is then trained using the feature matrix X and the residual errors
. Tree2 is then trained using the feature matrix X and the residual errors  of Tree1 as labels. The predicted results
of Tree1 as labels. The predicted results  are then used to determine the residual . The process is repeated until all the N trees forming the ensemble are trained.
are then used to determine the residual . The process is repeated until all the N trees forming the ensemble are trained.
Architecture
As we learned above that the key idea behind the Gradient Boosting algorithm is to take the simple, lower-order model as a kind of building block to build a more powerful, higher-order model by sequential boosting using first or second-order gradient statistics. In the Grownet, we use shallow neural networks (e.g., with one or two hidden layers) as weak learners.
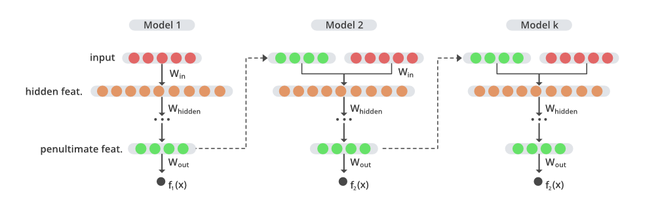
GrowNet architecture
In every boosting step, we combine the vectors of the original input features with output from the last layer of the current iteration. This new feature-set is then passed as input to train the next weak learner via boosting algorithm using current residuals. The final output of the model is a weighted combination of scores from all these sequentially trained weak learner models.
Let’s assume a dataset with n samples and d dimensional feature space D ={(x_i, y_i)_{i=1}^{n} | x_i \epsilon R^{d}, y_i \epsilon R}. Grownet uses K additive functions to predict the output:

where, f_k represents an independent, shallow weak learner with linear layer as output layer, a_k is the step size (boost rate).
Here, our objective function that the shallow learner need to minimize is following:

However, this objective function will not be enough because as similar to Gradient Boosting Decision Trees, the model is trained on an additive manner. Therefore, we need to add the output of the previous stage for sample  . Now, the output of the previous stage is:
. Now, the output of the previous stage is:

Therefore our objective function for stage t becomes:

The above objective function can be simplified as:

where, \widetilde{y_i} = -\frac{g_i}{h_i}, and gi and hi are first order gradient of objective function l at xi wrt \hat{y}_i^{t-1}. In the next step, we will be calculating the value of g and h for regression, classification and rank learning:
Regression
For regression, Let’s consider we apply the mse loss function and take l to represent it, then the formula for calculating different variables at stage t are:

Now, for the next weak learner f_t by least square regression on \left \{ x_i, \widetilde{y_i} \right \} for i =1, 2, 3, …. n. In the corrective step, all model parameters are back-propagated using MSE loss.
Classification
Let’s consider binary cross entropy loss as our loss function for the classification and labels such as y_i \epsilon {\left \{-1,1 \right \}} .This is because y_i^2 = 1 which can be used in our derivation. then the formula for calculating different variables at stage t are as follows:

Now, for the next weak learner f_t by least square regression on \left \{ x_i, \widetilde{y_i} \right \} using second order statistics. In the corrective step, all model parameters are back-propagated using e binary cross entropy loss.
Learn 2 rank
Learning to rank is an algorithmic strategy that is applied to supervised learning to solve ranking problems with respect to the relevancy of search queries. This is a very important search problem and has applications in many fields.
Let’s consider that for a given query, a pair of documents {Ui , Uj} is selected. Let’s take a feature vector for these documents, i.e {xi, xj}. Let  denote the output of the model for samples xi and xj respectively. A pairwise loss function for this query can be given as follows:
denote the output of the model for samples xi and xj respectively. A pairwise loss function for this query can be given as follows:

where,  if U_i has greater relevance than U_j , then S_{ij} =1. S_{ij} = -1 is then vice-versa of above relevance. S_{ij} =0, then it both will have equal relevance. \sigma_0 is the sigmoid function.
if U_i has greater relevance than U_j , then S_{ij} =1. S_{ij} = -1 is then vice-versa of above relevance. S_{ij} =0, then it both will have equal relevance. \sigma_0 is the sigmoid function.
Now, the loss function, first-order statistics, and second-order statistics can be derived as followed:

Corrective Step
In the previous boosting frameworks, each of the weak learners is greedily learned, i.e. the tth weak learner at boosting step t, whereas all the previous t-1 weak learners remain unchanged. In the corrective step, however, instead of fixing the previous t−1 weak learners, this model allows the update of the parameters of the previous t−1 weak learners through back-propagation. Moreover, a boosting rate  into parameters of the model and is automatically updated through the corrective step.
into parameters of the model and is automatically updated through the corrective step.
References:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...